
Ko sem začel delati s težavami s strojnim učenjem, sem v paniki, kateri algoritem naj uporabim? Ali katerega je enostavno uporabiti? Če ste takšni kot jaz, vam bo ta članek morda pomagal vedeti o algoritmih, metodah ali tehnikah umetne inteligence in strojnega učenja za reševanje nepričakovanih ali celo pričakovanih težav.
Strojno učenje je tako močna tehnika umetne inteligence, ki lahko nalogo učinkovito izvaja brez uporabe izrecnih navodil. Model ML se lahko uči iz svojih podatkov in izkušenj. Aplikacije za strojno učenje so samodejne, robustne in dinamične. Za reševanje te dinamične narave resničnih problemov je razvitih več algoritmov. Na splošno obstajajo tri vrste algoritmov strojnega učenja, kot so nadzorovano učenje, nenadzorovano učenje in učenje z okrepitvijo.
Najboljši algoritmi za umetno inteligenco in strojno učenje
Izbira ustrezne tehnike ali metode strojnega učenja je ena glavnih nalog za razvoj projekta umetne inteligence ali strojnega učenja. Na voljo je več algoritmov in vsi imajo svoje prednosti in uporabnost. Spodaj predstavljamo 20 algoritmov strojnega učenja tako za začetnike kot za profesionalce. Torej, poglejmo.
1. Naivni Bayes
Naivni Bayesov klasifikator je verjetnostni klasifikator, ki temelji na Bayesovem izreku, ob predpostavki neodvisnosti med značilnostmi. Te funkcije se razlikujejo od aplikacije do aplikacije. Za začetnike je ena izmed udobnih metod strojnega učenja.
Naivni Bayes je pogojni verjetnostni model. Glede na primerek problema, ki ga je treba razvrstiti, predstavlja vektor x = (xjaz … Xn) predstavlja nekaj n lastnosti (neodvisnih spremenljivk), sedanjim verjetnostim primernosti dodeli vsak K potencialni izid:
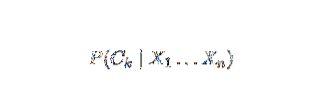 Težava z zgornjo formulacijo je v tem, da če je število značilnosti n pomembno ali če lahko element prevzame veliko število vrednosti, potem takšen model na verjetnostnih tabelah ni izvedljiv. Zato model ponovno razvijamo, da postane bolj uporaben. Z uporabo Bayesovega izreka lahko pogojno verjetnost zapišemo kot,
Težava z zgornjo formulacijo je v tem, da če je število značilnosti n pomembno ali če lahko element prevzame veliko število vrednosti, potem takšen model na verjetnostnih tabelah ni izvedljiv. Zato model ponovno razvijamo, da postane bolj uporaben. Z uporabo Bayesovega izreka lahko pogojno verjetnost zapišemo kot,
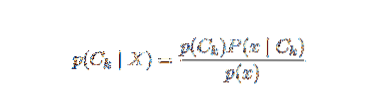
Z uporabo Bayesove verjetnostne terminologije lahko zgornjo enačbo zapišemo kot:
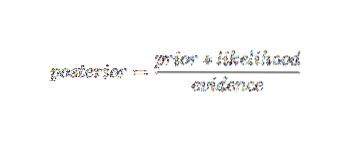
Ta algoritem umetne inteligence se uporablja pri razvrščanju besedil, tj.e., analiza razpoloženja, kategorizacija dokumentov, filtriranje neželene pošte in klasifikacija novic. Ta tehnika strojnega učenja deluje dobro, če so vhodni podatki razvrščeni v vnaprej določene skupine. Zahteva tudi manj podatkov kot logistična regresija. Izboljša se v različnih domenah.
2. Podporni vektorski stroj
Support Vector Machine (SVM) je eden najpogosteje uporabljenih nadzorovanih algoritmov strojnega učenja na področju razvrščanja besedil. Ta metoda se uporablja tudi za regresijo. Lahko se imenuje tudi podporna vektorska omrežja. Cortes & Vapnik sta to metodo razvila za binarno klasifikacijo. Nadzorovani učni model je pristop strojnega učenja, ki izhaja iz rezultatov označenih podatkov o vadbi.
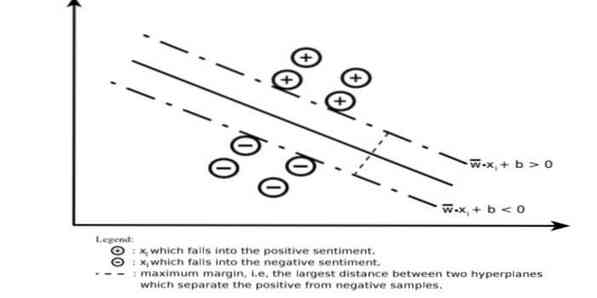
Stroj za podporni vektor izdela hiperravnino ali niz hiperravnin v zelo visokem ali neskončno dimenzionalnem območju. Izračuna linearno ločilno površino z največjo mejo za določen sklop vadbe.
Samo podmnožica vhodnih vektorjev bo vplivala na izbiro roba (obkrožen na sliki); taki vektorji se imenujejo podporni vektorji. Kadar linearna ločevalna površina ne obstaja, na primer ob prisotnosti hrupnih podatkov, so primerni algoritmi SVM s spremenljivo ohlapnostjo. Ta klasifikator poskuša podatkovni prostor razdeliti z uporabo linearnih ali nelinearnih razmejitev med različnimi razredi.
SVM se pogosto uporablja pri problemih klasifikacije vzorcev in nelinearni regresiji. Prav tako je ena najboljših tehnik za samodejno kategorizacijo besedil. Najboljše pri tem algoritmu je, da glede podatkov ne daje nobenih trdnih predpostavk.
Za izvedbo podpornega vektorskega stroja: Podatkovne knjižnice v Python-SciKit Learn, PyML, SVMStruktura Python, LIBSVM in Data Science Libraries v R- Klar, e1071.
3. Linearna regresija
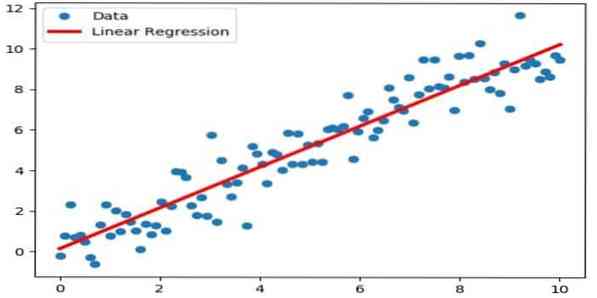
Linearna regresija je neposreden pristop, ki se uporablja za modeliranje razmerja med odvisno spremenljivko in eno ali več neodvisnimi spremenljivkami. Če obstaja ena neodvisna spremenljivka, jo imenujemo preprosta linearna regresija. Če je na voljo več kot ena neodvisna spremenljivka, se to imenuje večkratna linearna regresija.
Ta formula se uporablja za oceno realnih vrednosti, kot so cena domov, število klicev, skupna prodaja na podlagi neprekinjenih spremenljivk. Tu se razmerje med neodvisnimi in odvisnimi spremenljivkami vzpostavi z namestitvijo najboljše črte. Ta najbolj primerna črta je znana kot regresijska črta in jo predstavlja linearna enačba
Y = a * X + b.
tukaj,
- Y - odvisna spremenljivka
- a - naklon
- X - neodvisna spremenljivka
- b - prestrezanje
Ta metoda strojnega učenja je enostavna za uporabo. Izvaja se hitro. To lahko v poslu uporabite za napovedovanje prodaje. Uporablja se lahko tudi pri oceni tveganja.
4. Logistična regresija
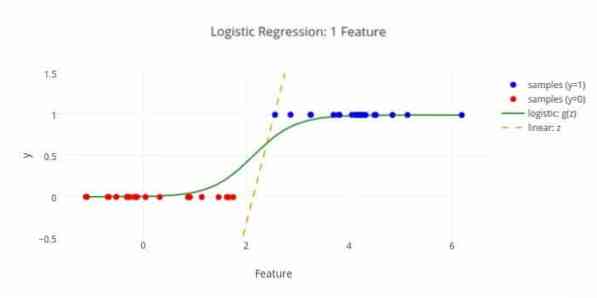
Tu je še en algoritem strojnega učenja - Logistična regresija ali logit regresija, ki se uporablja za oceno diskretnih vrednosti (binarne vrednosti, kot so 0/1, da / ne, res / ne) na podlagi danega nabora neodvisne spremenljivke. Naloga tega algoritma je predvideti verjetnost incidenta tako, da podatke prilagodi logit funkciji. Njegove izhodne vrednosti so med 0 in 1.
Formula se lahko uporablja na različnih področjih, kot so strojno učenje, znanstvena disciplina in medicinska področja. Uporablja se lahko za napovedovanje nevarnosti pojava določene bolezni na podlagi opazovanih značilnosti bolnika. Logistično regresijo lahko uporabimo za napovedovanje želje kupca po nakupu izdelka. Ta tehnika strojnega učenja se uporablja pri napovedovanju vremena za napovedovanje verjetnosti dežja.
Logistično regresijo lahko razdelimo na tri vrste -
- Binarna logistična regresija
- Več nominalna logistična regresija
- Redna logistična regresija
Logistična regresija je manj zapletena. Prav tako je robusten. Obvladuje lahko nelinearne učinke. Če pa so podatki o vadbi redki in visoko dimenzionalni, lahko ta algoritem ML preveč ustreza. Ne more napovedati stalnih rezultatov.
5. K-najbližji-sosed (KNN)
K-najbližji sosed (kNN) je dobro znan statistični pristop za razvrščanje in je bil v preteklih letih široko preučevan in že zgodaj uporabljen pri nalogah kategorizacije. Deluje kot neparametrična metodologija za razvrščanje in regresijske probleme.
Ta metoda AI in ML je precej preprosta. Določa kategorijo testnega dokumenta t na podlagi glasovanja o nizu k dokumentov, ki so najbližji t glede na razdaljo, običajno evklidsko razdaljo. Bistveno pravilo odločitve za preskusni dokument t za klasifikator kNN je:
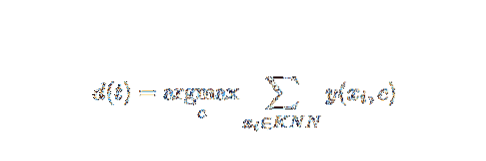
Kjer je y (xi, c) binarna klasifikacijska funkcija za dokument usposabljanja xi (ki vrne vrednost 1, če je xi označen s c ali 0 drugače), to pravilo označi s t s kategorijo, ki ima največ glasov v k -najbližja soseska.
KNN nas lahko preslika v naše resnično življenje. Če bi na primer želeli izvedeti nekaj ljudi, o katerih nimate podatkov, bi se raje odločili glede njegovih bližnjih prijateljev in torej krogov, v katerih se premika, ter pridobiti dostop do njegovih / njenih informacij. Ta algoritem je računsko drag.
6. K-pomeni
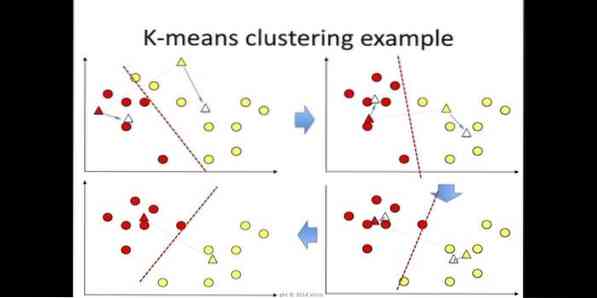
združevanje k-pomeni je metoda nenadzorovanega učenja, ki je dostopna za analizo grozdov pri podatkovnem rudarjenju. Namen tega algoritma je razdeliti n opazovanj na k grozdov, kjer vsako opazovanje pripada najbližji srednji vrednosti grozda. Ta algoritem se uporablja pri segmentaciji trga, računalniškem vidu in astronomiji med številnimi drugimi področji.
7. Drevo odločanja
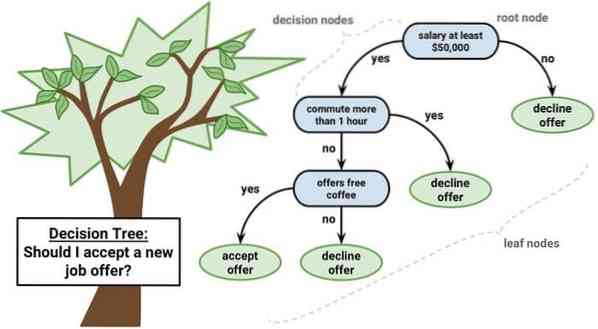
Drevo odločanja je orodje za podporo odločanju, ki uporablja grafični prikaz, tj.e., drevesni graf ali model odločitev. Pogosto se uporablja pri analizi odločitev in je tudi priljubljeno orodje pri strojnem učenju. Drevesa odločitev se uporabljajo pri operativnih raziskavah in upravljanju operacij.
Ima strukturo, podobno diagramu poteka, v katerem vsako notranje vozlišče predstavlja 'test' atributa, vsaka veja predstavlja rezultat testa, vsako listno vozlišče pa oznako razreda. Pot od korena do lista je znana kot pravila razvrščanja. Sestavljen je iz treh vrst vozlišč:
- Vozlišča odločanja: običajno so predstavljena s kvadratki,
- Vozlišča naključja: običajno jih predstavljajo krogi,
- Končna vozlišča: običajno predstavljena s trikotniki.
Drevo odločanja je enostavno razumeti in razložiti. Uporablja model bele škatle. Prav tako se lahko kombinira z drugimi tehnikami odločanja.
8. Naključni gozd
Naključni gozd je priljubljena tehnika ansambelnega učenja, ki deluje tako, da v času treninga gradi množico dreves odločanja in izpiše kategorijo, ki je način kategorij (klasifikacija) ali povprečna napoved (regresija) vsakega drevesa.
Ta algoritem strojnega učenja deluje hitro in lahko deluje z neuravnoteženimi in manjkajočimi podatki. Ko pa smo ga uporabili za regresijo, ne more napovedati preko obsega v podatkih o vadbi in lahko podatke preveč prilega.
9. VOZIČEK
Drevo klasifikacije in regresije (CART) je ena vrsta dreves odločanja. Drevo odločitev deluje kot pristop rekurzivnega razdeljevanja in CART vsako vhodno vozlišče razdeli na dva podrejena vozlišča. Na vsaki ravni odločitvenega drevesa algoritem opredeli pogoj - katero spremenljivko in raven uporabiti za razdelitev vhodnega vozlišča na dva podrejena vozlišča.
Koraki algoritma CART so navedeni spodaj:
- Vzemi vhodne podatke
- Najboljši Split
- Najboljša spremenljivka
- Vhodne podatke razdelite na levo in desno vozlišče
- Nadaljujte s korakom 2-4
- Obrezovanje drevesa odločitev
10. Algoritem strojnega učenja Apriori

Apriorijev algoritem je algoritem za kategorizacijo. Ta tehnika strojnega učenja se uporablja za razvrščanje velikih količin podatkov. Uporablja se lahko tudi za spremljanje razvoja odnosov in grajenja kategorij. Ta algoritem je nenadzorovana učna metoda, ki generira pravila pridružitve iz danega nabora podatkov.
Apriori algoritem strojnega učenja deluje kot:
- Če se nabor elementov pojavlja pogosto, se pogosto dogajajo tudi vsi podnabori nabora elementov.
- Če se nabor elementov pojavlja redko, se redko pojavljajo tudi vse nadmnožice nabora elementov.
Ta algoritem ML se uporablja v različnih aplikacijah, na primer za odkrivanje neželenih učinkov zdravil, za analizo tržne košarice in samodejno dokončanje aplikacij. Izvedba je enostavna.
11. Analiza glavne komponente (PCA)
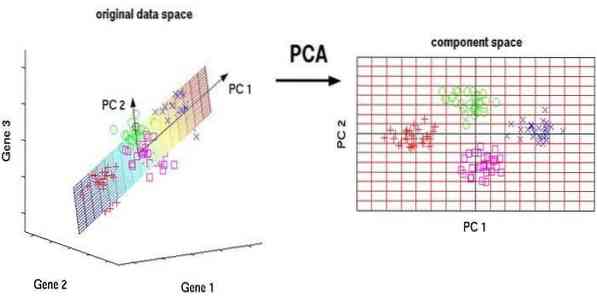
Analiza glavnih komponent (PCA) je nenadzorovani algoritem. Nove funkcije so pravokotne, kar pomeni, da niso povezane. Pred izvajanjem PCA morate vedno normalizirati nabor podatkov, ker je preoblikovanje odvisno od obsega. Če tega ne storite, bodo funkcije, ki so najpomembnejše, prevladovale med novimi glavnimi komponentami.
PCA je vsestranska tehnika. Ta algoritem je enostaven in enostaven za uporabo. Uporablja se lahko za obdelavo slik.
12. CatBoost
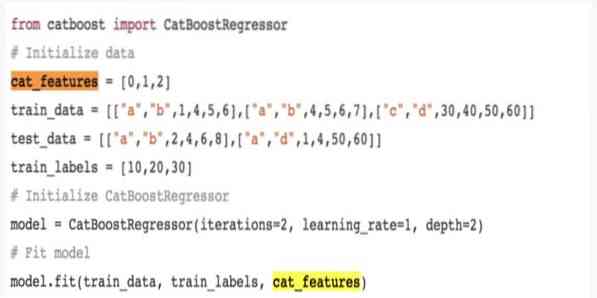
CatBoost je odprtokodni algoritem strojnega učenja, ki prihaja iz Yandexa. Ime "CatBoost" izhaja iz dveh besed "Category" in "Boosting".„Lahko se kombinira z globokimi učnimi okviri, tj.e., Googlova TensorFlow in Appleov Core ML. CatBoost lahko s številnimi vrstami podatkov reši več težav.
13. Iterativni dihotomizator 3 (ID3)
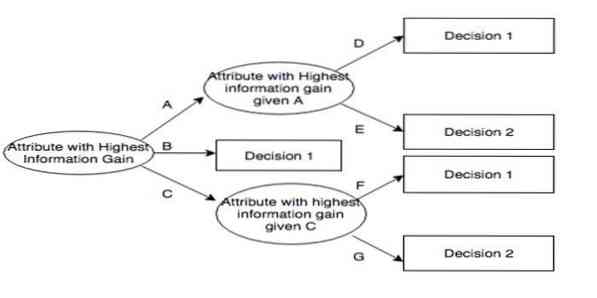
Iterative Dichotomiser 3 (ID3) je algoritemsko pravilo učenja dreves odločanja, ki ga je predstavil Ross Quinlan in je uporabljeno za dobavo drevesa odločitev iz nabora podatkov. Je predhodnik C4.5 algoritemski program in je zaposlen na področjih strojnega učenja in jezikovnih komunikacij.
ID3 se lahko preveč prilega podatkom o vadbi. To algoritemsko pravilo je težje uporabiti pri neprekinjenih podatkih. Ne zagotavlja optimalne rešitve.
14. Hierarhično grozdenje
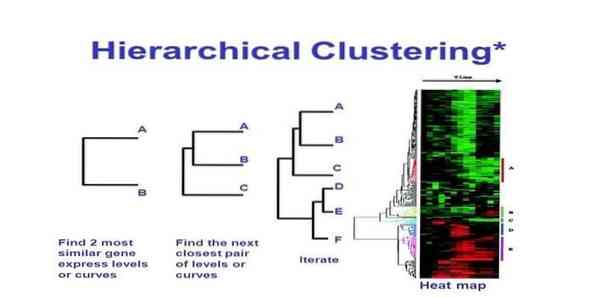
Hierarhično združevanje je način analize grozdov. V hierarhičnem združevanju je razvito drevo grozdov (dendrogram) za ponazoritev podatkov. V hierarhičnem združevanju se vsaka skupina (vozlišče) poveže z dvema ali več naslednimi skupinami. Vsako vozlišče znotraj drevesa gruče vsebuje podobne podatke. Vozlišča se na grafu združijo z drugimi podobnimi vozlišči.
Algoritem
To metodo strojnega učenja lahko razdelimo na dva modela - od spodaj navzgor ali od zgoraj navzdol:
Od spodaj navzgor (Hierarhično strnjeno združevanje v gruče, HAC)
- Na začetku te tehnike strojnega učenja vzemite vsak dokument kot eno skupino.
- V novi gruči združite dva elementa hkrati. Način združevanja kombinacij vključuje računsko razliko med vsakim vgrajenim parom in s tem alternativnimi vzorci. Za to obstaja veliko možnosti. Nekateri med njimi so:
a. Popolna povezava: Podobnost najbolj oddaljenega para. Ena omejitev je, da lahko odstopanja povzročijo združitev tesnih skupin pozneje, kot je optimalno.
b. Enojna povezava: Podobnost najbližjega para. Lahko povzroči prezgodnje združevanje, čeprav so te skupine precej različne.
c. Povprečje skupine: podobnost med skupinami.
d. Podobnost centroida: vsaka ponovitev združi grozde s skrajno podobno osrednjo točko.
- Dokler se vsi elementi ne združijo v eno skupino, postopek seznanjanja poteka.
Od zgoraj navzdol (grozdno deljenje)
- Podatki se začnejo s kombinirano skupino.
- Grozd se glede na določeno stopnjo podobnosti deli na dva različna dela.
- Gruče se vedno znova delijo na dva, dokler gruče ne vsebujejo samo ene podatkovne točke.
15. Razmnoževanje
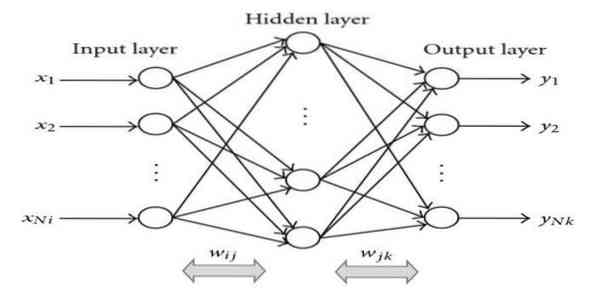
Razmnoževanje je nadzorovan učni algoritem. Ta algoritem ML prihaja s področja ANN (Umetna nevronska omrežja). To omrežje je večplastno povratno omrežje. Cilj te tehnike je oblikovanje dane funkcije s spreminjanjem notranjih uteži vhodnih signalov, da se ustvari želeni izhodni signal. Uporablja se lahko za klasifikacijo in regresijo.

Algoritem povratnega širjenja ima nekaj prednosti, tj.e., je enostaven za izvedbo. Matematična formula, uporabljena v algoritmu, se lahko uporabi za katero koli omrežje. Čas računanja se lahko skrajša, če so uteži majhne.
Algoritem povratnega razmnoževanja ima nekaj pomanjkljivosti, na primer, da je občutljiv na hrupne podatke in odstopanja. Gre za popolnoma matrični pristop. Dejanska zmogljivost tega algoritma je v celoti odvisna od vhodnih podatkov. Izhod je lahko numeričen.
16. AdaBoost
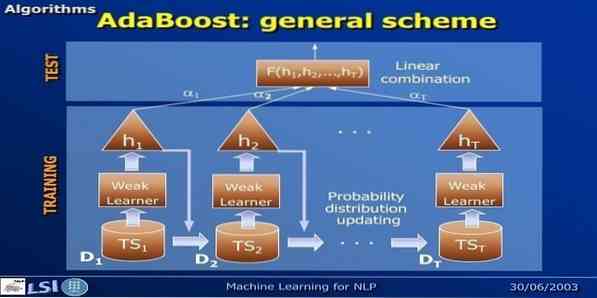
AdaBoost pomeni Adaptive Boosting, metodo strojnega učenja, ki jo zastopata Yoav Freund in Robert Schapire. Je meta-algoritem in ga je mogoče integrirati z drugimi učnimi algoritmi za izboljšanje njihove učinkovitosti. Ta algoritem je hiter in enostaven za uporabo. Dobro deluje z velikimi nabori podatkov.
17. Globoko učenje
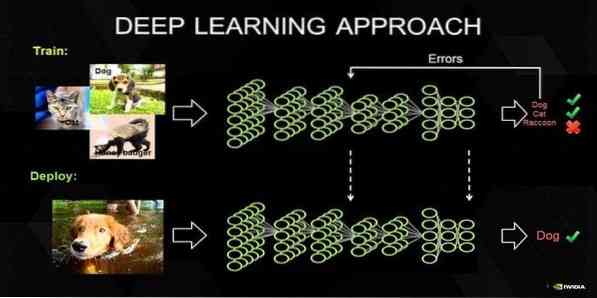
Poglobljeno učenje je skupek tehnik, ki jih navdihuje mehanizem človeških možganov. Dva osnovna globoka učenja, tj.e., Pri klasifikaciji besedil se uporabljata nevronska konvolucijska omrežja (CNN) in ponavljajoča se nevronska omrežja (RNN). Za pridobivanje vektorskih predstavitev besed in izboljšanje natančnosti klasifikatorjev, ki so usposobljeni s tradicionalnimi algoritmi strojnega učenja, se uporabljajo tudi algoritmi globokega učenja, kot sta Word2Vec ali GloVe.
Ta metoda strojnega učenja potrebuje veliko vzorca usposabljanja namesto tradicionalnih algoritmov strojnega učenja, tj.e., najmanj milijonov označenih primerov. Nasprotno pa tradicionalne tehnike strojnega učenja dosežejo natančen prag, kadar dodajanje več vzorca vadbe na splošno ne izboljša njihove natančnosti. Klasifikatorji globokega učenja presegajo boljše rezultate z več podatki.
18. Algoritem za povečanje gradienta

Gradient boosting je metoda strojnega učenja, ki se uporablja za klasifikacijo in regresijo. Je eden najmočnejših načinov za razvoj napovednega modela. Algoritem za povečanje gradienta ima tri elemente:
- Funkcija izgube
- Šibek učenec
- Aditivni model
19. Omrežje Hopfield
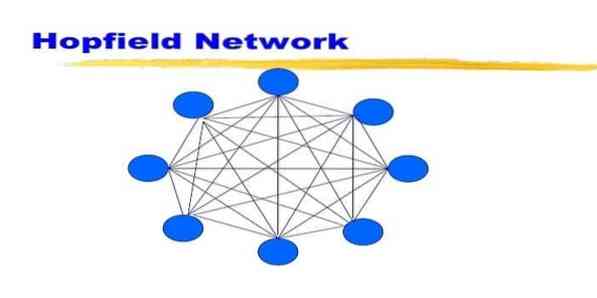
Hopfieldova mreža je ena vrsta ponavljajočih se umetnih nevronskih mrež, ki jo je John Hopfield dal leta 1982. Cilj tega omrežja je shraniti enega ali več vzorcev in priklicati celotne vzorce na podlagi delnega vnosa. V omrežju Hopfield so vsa vozlišča hkrati vhodi in izhodi ter popolnoma povezana.
20. C4.5

C4.5 je drevo odločanja, ki ga je izumil Ross Quinlan. Njegova nadgradnja različice ID3. Ta algoritemski program zajema nekaj osnovnih primerov:
- Vsi vzorci s seznama spadajo v podobno kategorijo. Ustvari listno vozlišče za drevo odločanja, ki pravi, da se mora odločiti za to kategorijo.
- Ustvari vozlišče odločitve višje po drevesu z uporabo pričakovane vrednosti razreda.
- Ustvari vozlišče odločitve višje po drevesu z uporabo pričakovane vrednosti.
Konec misli
Zelo pomembno je, da za razvoj učinkovitega projekta strojnega učenja uporabite ustrezen algoritem, ki temelji na vaših podatkih in domeni. Razumevanje kritične razlike med vsakim algoritmom strojnega učenja je ključnega pomena, da se ga lotim, "ko izberem katerega.„Tako kot se je pri pristopu strojnega učenja stroj ali naprava naučila z učnim algoritmom. Trdno sem prepričan, da vam ta članek pomaga razumeti algoritem. Če imate kakršen koli predlog ali vprašanje, vas prosimo, da vprašate. Nadaljujte z branjem.


