Kadar želimo v našo aplikacijo vključiti posrednike sporočil, ki nam omogočajo enostavno prilagajanje in asinhronost povezave našega sistema, obstaja veliko posrednikov sporočil, ki lahko izberejo enega izmed vas, na primer:
- RabbitMQ
- Apache Kafka
- ActiveMQ
- AQS SQS
- Redis
Vsak od teh posrednikov sporočil ima svoj seznam prednosti in slabosti, a najbolj zahtevni možnosti sta prvi dve, RabbitMQ in Apache Kafka. V tej lekciji bomo našteli točke, ki lahko pomagajo zožiti odločitev, da gremo drug proti drugemu. Na koncu velja še poudariti, da nobena od teh v vseh primerih uporabe ni boljša od druge in je popolnoma odvisna od tega, kaj želite doseči, zato ni pravega odgovora!
Začeli bomo s preprosto predstavitvijo teh orodij.
Apache Kafka
Kot smo že povedali v tej lekciji, je Apache Kafka distribuiran dnevnik oddaj, odporen na napake, vodoravno prilagodljiv. To pomeni, da lahko Kafka zelo dobro izvaja izraz »deli in vladaj«, lahko ponovi vaše podatke, da zagotovi razpoložljivost, in je zelo prilagodljiv v smislu, da lahko med izvajanjem vključite nove strežnike, da povečate svojo sposobnost upravljanja več sporočil.
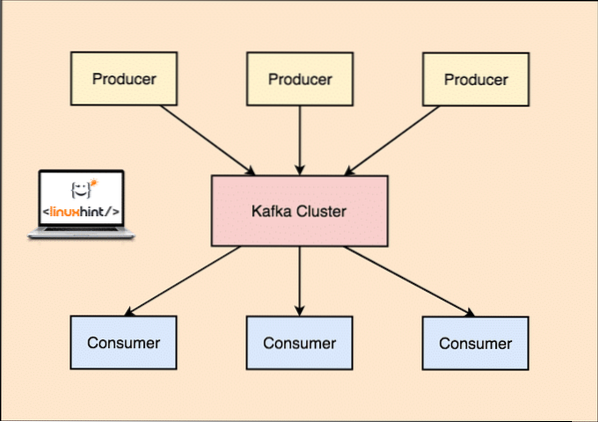
Kafka proizvajalec in potrošnik
RabbitMQ
RabbitMQ je bolj splošen in enostavnejši posrednik za sporočila, ki sam beleži, katera sporočila je stranka porabila, in vztraja pri drugem. Tudi če strežnik RabbitMQ iz nekega razloga propade, ste lahko prepričani, da so bila sporočila, ki so trenutno prisotna v čakalnih vrstah, shranjena v datotečnem sistemu, tako da lahko uporabniki, ko se RabbitMQ znova prikaže, ta sporočila dosledno obdelajo.
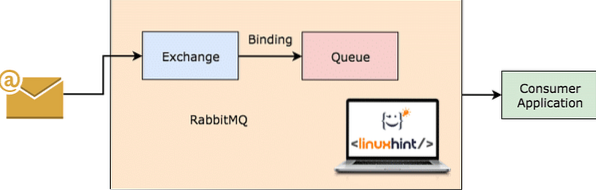
RabbitMQ deluje
Velesila: Apache Kafka
Glavna Kafkina velesila je, da jo lahko uporabimo kot sistem čakalnih vrst, vendar to ni le tisto, kar je omejeno. Kafka je nekaj bolj podobnega krožni odbojnik ki lahko meri toliko kot disk na stroju na gruči in nam tako omogoča, da lahko ponovno beremo sporočila. To lahko stori odjemalec, ne da bi moral biti odvisen od grozda Kafka, saj je stranka popolnoma odgovorna, da si zabeleži metapodatke sporočila, ki jih trenutno bere, in lahko pozneje v določenem intervalu ponovno obišče Kafko, da ponovno prebere isto sporočilo.
Upoštevajte, da je čas, v katerem je mogoče to sporočilo znova prebrati, omejen in ga je mogoče konfigurirati v konfiguraciji Kafka. Ko je čas torej končan, odjemalec nikoli več ne more prebrati starejšega sporočila.
Velesila: RabbitMQ
Glavna velesila RabbitMQ je, da je preprosto razširljiva, je visoko zmogljiv sistem čakalnih vrst, ki ima zelo natančno določena pravila skladnosti in sposobnost ustvarjanja številnih vrst modelov za izmenjavo sporočil. Na primer, v RabbitMQ lahko ustvarite tri vrste izmenjave:
- Neposredna izmenjava: ena do ena izmenjava tem
- Izmenjava tem: A temo je določeno, na katerem lahko različni proizvajalci objavijo sporočilo, različni potrošniki pa se lahko zavežejo, da bodo poslušali to temo, zato vsak od njih prejme sporočilo, ki je poslano tej temi.
- Izmenjava oboževalcev: To je bolj strogo kot izmenjava tem, saj ob objavi sporočila na izmenjavi navijačev sporočilo prejmejo vsi potrošniki, ki so povezani v čakalne vrste, ki se vežejo na izmenjavo oboževalcev.
Že opazil razliko med RabbitMQ in Kafko? Razlika je v tem, da če potrošnik ob objavi sporočila ni povezan z izmenjavo oboževalcev v RabbitMQ, bo izgubljen, ker so ga porabili drugi potrošniki, vendar se to v Apache Kafka ne zgodi, saj lahko vsak potrošnik prebere katero koli sporočilo. kot ohranijo lastni kurzor.
RabbitMQ je osredotočen na posrednika
Dober posrednik je nekdo, ki jamči za svoje delo in v tem je RabbitMQ dober. Nagnjen je proti garancije za dostavo med proizvajalci in potrošniki, s prehodnimi prednostmi pred trajnimi sporočili.
RabbitMQ uporablja samega posrednika za upravljanje stanja sporočila in zagotavlja, da je vsako sporočilo dostavljeno vsakemu upravičenemu potrošniku.
RabbitMQ domneva, da so potrošniki večinoma na spletu.
Kafka je osredotočen na proizvajalca
Apache Kafka je osredotočen na proizvajalca, saj v celoti temelji na particioniranju in toku paketov dogodkov, ki vsebujejo podatke, in jih pretvori v trajne posrednike sporočil s kazalci, ki podpirajo paketne potrošnike, ki so morda brez povezave, ali spletne potrošnike, ki želijo sporočila z majhno zakasnitvijo.
Kafka zagotavlja, da sporočilo ostane varno do določenega časovnega obdobja, tako da sporočilo podvoji na svojih vozliščih v gruči in vzdržuje konsistentno stanje.
Torej, Kafka ne domnevamo, da je kateri od njegovih potrošnikov večinoma na spletu in ga tudi ne zanima.
Naročanje sporočil
Pri RabbitMQ je naročilo založništva se vodi dosledno potrošniki pa bodo sporočilo prejeli v objavljenem naročilu. Po drugi strani Kafka tega ne počne, saj domneva, da so objavljena sporočila težka, zato so potrošniki počasni in lahko pošiljajo sporočila v poljubnem vrstnem redu, zato naročila tudi ne upravlja sam. Lahko pa nastavimo podobno topologijo za upravljanje vrstnega reda v Kafki s pomočjo dosledna izmenjava razprševanja ali vtičnik za ostrenje., ali celo več vrst topologij.
Popolna naloga, ki jo upravlja Apache Kafka, je, da deluje kot »blažilec sunkov« med neprekinjenim tokom dogodkov in potrošniki, med katerimi so nekateri na spletu, drugi pa lahko brez povezave - porabijo samo serije na uro ali celo dnevno.
Zaključek
V tej lekciji smo preučevali glavne razlike (in podobnosti tudi) med Apachejem Kafko in RabbitMQ. V nekaterih okoljih sta oba pokazala izjemno zmogljivost, na primer RabbitMQ porabi milijone sporočil na sekundo, Kafka pa nekaj milijonov sporočil na sekundo. Glavna arhitekturna razlika je v tem, da RabbitMQ sporočila upravlja skoraj v pomnilniku, zato uporablja veliko skupino (več kot 30 vozlišč), medtem ko Kafka dejansko izkorišča moči zaporednih vhodno / izhodnih operacij diska in zahteva manj strojne opreme.
Spet je uporaba vsakega od njih še vedno popolnoma odvisna od primera uporabe v aplikaciji. Vesela sporočila !


