Prevajanje in zagon R iz ukazne vrstice
Dva načina za zagon programov R sta: skript R, ki se pogosto uporablja in je najbolj zaželen, drugi pa R CMD BATCH, ni pogosto uporabljen ukaz. Pokličemo jih lahko neposredno iz ukazne vrstice ali katerega koli drugega načrtovalca opravil.
Te ukaze lahko pokličete iz lupine, vgrajene v IDE, danes pa RStudio IDE prihaja z orodji, ki izboljšujejo ali upravljajo funkcije R skripta in R CMD BATCH.
funkcija source () znotraj R je dobra alternativa uporabi ukazne vrstice. Ta funkcija lahko pokliče tudi skript, toda za uporabo te funkcije morate biti v okolju R.
Vgrajeni podatkovni nizi v jeziku R
Če želite navesti nabore podatkov, ki so vgrajeni z R, uporabite ukaz data (), nato poiščite, kar želite, in uporabite ime nabora podatkov v funkciji data (). Podobni podatki (ime funkcije).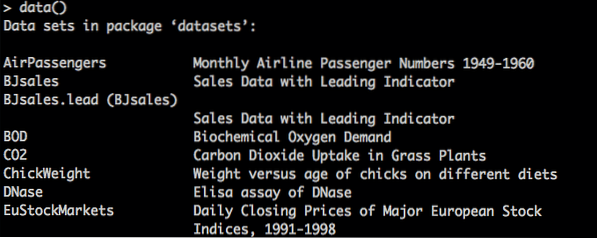
Prikaži nabore podatkov v R
Vprašaj (?) bi lahko uporabili za pomoč pri naborih podatkov.
Za preverjanje vsega uporabite povzetek ().
Plot () je tudi funkcija, ki se uporablja za risanje grafov.
Ustvarimo testni skript in ga zaženimo. Ustvari p1.R datoteko in jo shranite v domači imenik z naslednjo vsebino:
Primer kode:
# Preprosta zdrava koda svetovnega tiska v R print ("Hello World!") print (" LinuxHint ") print (5 + 6) 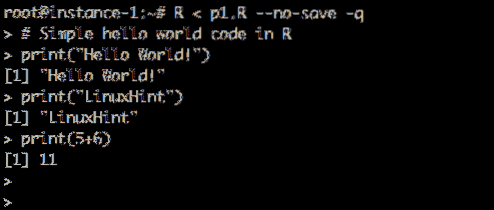
Tek Hello World
R Podatkovni okviri
Za shranjevanje podatkov v tabelah uporabljamo strukturo v R, imenovano a Podatkovni okvir. Uporablja se za navajanje vektorjev enake dolžine. Na primer, naslednja spremenljivka nm je podatkovni okvir, ki vsebuje tri vektorje x, y, z:
x = c (2, 3, 5) y = c ("aa", "bb", "cc") z = c (TRUE, FALSE, TRUE) # nm je podatkovni okvir nm = data.okvir (n, s, b) Obstaja koncept, imenovan VgrajenPodatkovni okviri tudi v R. mtcars je en tak vgrajen podatkovni okvir v R, ki ga bomo uporabili kot primer za boljše razumevanje. Glejte spodnjo kodo:
> mtcars mpg cyl disp hp drat wt ... Mazda RX4 21.0 6 160 110 3.90 2.62… avtobus RX4 Wag 21.0 6 160 110 3.90 2.88… Datsun 710 22.8 4 108 93 3.85 2.32…
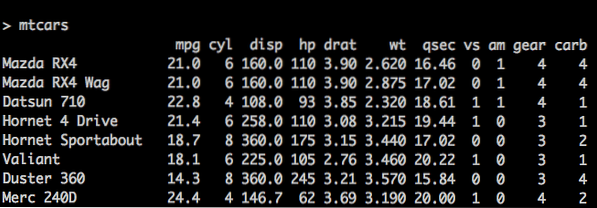
mtcars bulitin podatkovni okvir
Glava je zgornja vrstica tabele, ki vsebuje imena stolpcev. Podatkovne vrstice podari vsaka vodoravna črta; vsaka vrstica se začne z imenom vrstice, ki ji sledijo dejanski podatki. Podatkovni član vrstice se imenuje celica.
Koordinate vrstic in stolpcev bi vnesli v en operator kvadratnega oklepaja '[]' za pridobivanje podatkov v celici. Za ločevanje koordinat uporabljamo vejico. Vrstni red je bistvenega pomena. Koordinata se začne z vrstico, nato vejico in nato konča s stolpcem. Vrednost celice 2nd vrstica in 1st stolpec je podan kot:
> mtcars [2, 2] [1] 6
Namesto koordinat lahko uporabimo tudi ime vrstice in stolpca:
> mtcars ["Bus RX4", "mpg"] [1] 6
Nrow funkcija se uporablja za iskanje števila vrstic v podatkovnem okviru.
> nrow (mtcars) # število podatkovnih vrstic [1] 32
Funkcija ncol se uporablja za iskanje števila stolpcev v podatkovnem okviru.
> ncol (mtcars) # število stolpcev [1] 11
R Programske zanke
Pod določenimi pogoji zanke uporabljamo, kadar želimo avtomatizirati določen del kode ali ponoviti zaporedje navodil.
Za zanko v R
Če želimo podatke o teh letih natisniti več kot enkrat.
print (prilepi ("Leto je", 2000)) "Leto je 2000" natisni (prilepi ("Leto je", 2001)) "Leto je 2001" natisni (prilepi ("Leto je", 2002) ) "Leto je 2002" tisk (prilepi ("Leto je", 2003)) "Leto je 2003" natisni (prilepi ("Leto je", 2004)) "Leto je 2004" natisni (prilepi (" Leto je ", 2005))" Leto je 2005 " Namesto da vedno znova ponavljamo svojo izjavo, če jo uporabimo za zanko nam bo veliko lažje. Všečkaj to:
za (leto v c (2000,2001,2002,2003,2004,2005)) print (prilepi ("Leto je", leto)) "Leto je 2000" "Leto je 2001" "Leto je 2002 "" Leto je 2003 "" Leto je 2004 "" Leto je 2005 " Medtem ko Loop v R
while (izraz) stavek
Če je rezultat izraza TRUE, se vnese telo zanke. Izvedejo se stavki znotraj zanke, tok pa se vrne, da znova oceni izraz. Zanka se bo ponavljala, dokler izraz ne bo ocenjen na FALSE, v tem primeru zanka zapusti.
Primer while Loop:
# i se na začetku inicializira na 0 i = 0, medtem ko (i<5) print (i) i=i+1 Output: 0 1 2 3 4
V zgornji zanki while je izraz jaz<5ki meri na TRUE, saj je 0 manj kot 5. Zato je telo zanke izvedeno in jaz se izpiše in poveča. Pomembno je povečati jaz znotraj zanke, tako da bo na neki točki nekako izpolnil pogoj. V naslednji zanki vrednost jaz je 1 in zanka se nadaljuje. Ponavljalo se bo do jaz je enako 5, ko je pogoj 5<5 reached loop will give FALSE and the while loop will exit.
R funkcije
Če želite ustvariti a funkcijo uporabljamo funkcijo direktive (). Natančneje, gre za R predmete razreda funkcijo.
f <- function() ##some piece of instructions
Funkcije lahko zlasti posredujemo drugim funkcijam, saj lahko argumente in funkcije vgnezdimo, da lahko določite funkcijo znotraj druge funkcije.
Funkcije imajo po izbiri lahko nekatere imenovane argumente, ki imajo privzete vrednosti. Če ne želite privzete vrednosti, lahko nastavite njeno vrednost na NULL.
Nekaj dejstev o argumentih funkcije R:
- Argumenti, sprejeti v definiciji funkcije, so formalni argumenti
- Funkcija formals lahko vrne seznam vseh formalnih argumentov funkcije
- Vsak klic funkcije v R ne uporablja vseh formalnih argumentov
- Argumenti funkcije imajo lahko privzete vrednosti ali pa manjkajo
#Opredelitev funkcije: f <- function (x, y = 1, z = 2, s= NULL)
Izdelava logističnega regresijskega modela z vgrajenim naborom podatkov
The glm () funkcija se uporablja v R, da ustreza logistični regresiji. Funkcija glm () je podobna funkciji lm (), vendar ima glm () nekaj dodatnih parametrov. Njegova oblika je videti tako:
glm (X ~ Z1 + Z2 + Z3, družina = binom (povezava = "logit"), podatki = podatki)
X je odvisen od vrednosti Z1, Z2 in Z3. Kar pomeni, da so Z1, Z2 in Z3 neodvisne spremenljivke, X pa odvisna funkcija vključuje družino dodatnih parametrov in ima vrednost binom (link = “logit”), kar pomeni, da je funkcija link logit, verjetnostna porazdelitev regresijskega modela pa binomna.
Recimo, da imamo primer študenta, kjer bo dobil sprejem na podlagi dveh izpitnih rezultatov. Nabor podatkov vsebuje naslednje postavke:
- rezultat _1- Rezultat-1 rezultat
- rezultat _2- Rezultat -2 rezultat
- sprejeto - 1 če je sprejeto ali 0, če ni sprejeto
V tem primeru imamo dve vrednosti 1, če je študent dobil sprejem in 0, če ni dobil sprejema. Ustvariti moramo model za napovedovanje, ali je študent dobil sprejem ali ne,. Pri danem problemu se šteje, da je sprejeto kot odvisna spremenljivka, izpit_1 in izpit_2 pa kot neodvisni spremenljivki. Za ta model je podana naša koda R
> Model_1<-glm(admitted ~ result_1 +result_2, family = binomial("logit"), data=data) Predpostavimo, da imamo dva rezultata študenta. Rezultat-1 65% in rezultat-2 90%, zdaj bomo predvideli, da študent dobi sprejem ali ne, za oceno verjetnosti študenta, da bi sprejel našo kodo R je spodaj:
> in_frame<-data.frame(result_1=65,result_2=90) >napoved (Model_1, in_frame, type = "response") Izhod: 0.9894302
Zgornji rezultat prikazuje verjetnost med 0 in 1. Če je potem manj kot 0.5 to pomeni, da študent ni dobil sprejema. V tem stanju bo LAŽNO. Če je večja od 0.5 bo pogoj veljal za TRUE, kar pomeni, da ima študent sprejem. Za napoved verjetnosti med 0 in 1 moramo uporabiti funkcijo round ().
Koda R za to je prikazana spodaj:
> krog (napovedi (Model_1, in_frame, type = "response")) [/ code] Izhod: 1
Študent bo dobil sprejem, saj je rezultat 1. Poleg tega lahko na enak način predvidevamo tudi druga opazovanja.
Uporaba logističnega regresijskega modela (točkovanje) z novimi podatki
Po potrebi lahko model shranimo v datoteko. Koda R za naš model vlaka bo videti tako:
the_model <- glm(my_formula, family=binomial(link='logit'),data=model_set)
Ta model lahko shranite z:
shrani (datoteka = "ime datoteke", datoteka_datoteke)
Datoteko lahko uporabite po tem, ko jo shranite z uporabo te kode miru R:
naloži (datoteka = "ime datoteke")
Za uporabo modela za nove podatke lahko uporabite to vrstico kode:
model_nabora $ pred <- predict(the_model, newdata=model_set, type="response")
OPOMBA: Nabora modelov ni mogoče dodeliti nobeni spremenljivki. Za nalaganje modela bomo uporabili funkcijo load (). Nova opažanja v modelu ne bodo ničesar spremenila. Model bo ostal enak. Stari model uporabljamo za napovedovanje novih podatkov, da ne bi ničesar spremenili v modelu.
Zaključek
Upam, da ste videli, kako programiranje R deluje na osnovni način in kako lahko hitro začnete z izvajanjem strojnega učenja in kodiranja statistik z R.


