V tej lekciji bomo obravnavali tri glavne teme:
- Kaj so tenzorji in TensorFlow
- Uporaba algoritmov ML s TensorFlow
- Primeri uporabe TensorFlow
TensorFlow je odličen Googlov paket Python, ki dobro uporablja paradigmo programiranja pretoka podatkov za zelo optimizirane matematične izračune. Nekatere značilnosti TensorFlow-a so:
- Zmogljivost porazdeljenega računanja, ki olajša upravljanje podatkov v velikih sklopih
- Podpora za globoko učenje in nevronske mreže je dobra
- Zelo učinkovito upravlja z zapletenimi matematičnimi strukturami, kot so n-dimenzionalni nizi
Zaradi vseh teh funkcij in obsega algoritmov strojnega učenja TensorFlow uporablja knjižnico obsega proizvodnje. Potopimo se v koncepte v TensorFlowu, da si bomo lahko takoj po umazali roke s kodo.
Namestitev TensorFlow
Ker bomo uporabili Python API za TensorFlow, je dobro vedeti, da deluje z obema Python 2.7 in 3.3+ različice. Namestite knjižnico TensorFlow, preden preidemo na dejanske primere in koncepte. Ta paket lahko namestite na dva načina. Prva vključuje uporabo upravitelja paketov Python, pip:
pip namestiteDrugi način se nanaša na Anacondo, paket lahko namestimo kot:
conda install -c conda-forge tensorflowNa uradnih straneh za namestitev TensorFlow lahko iščete nočne gradnje in različice grafičnega procesorja.
Za vse primere v tej lekciji bom uporabil upravitelja Anaconde. Za isto bom izdal Jupyter Notebook:

Zdaj, ko smo pripravljeni z vsemi izjavami o uvozu napisati nekaj kode, se začnimo potapljati v paket SciPy z nekaj praktičnimi primeri.
Kaj so tenzorji?
Tenzorji so osnovne podatkovne strukture, ki se uporabljajo v programu Tensorflow. Da, so le način za predstavitev podatkov v globokem učenju. Predstavljajmo si jih tukaj:
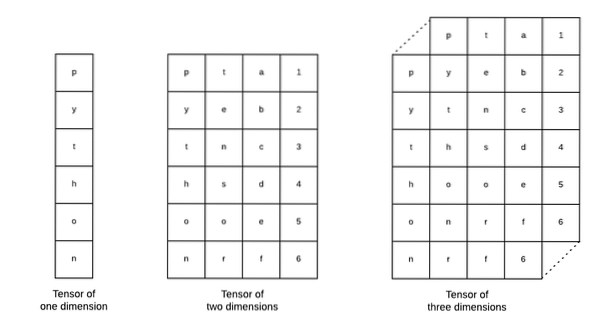
Kot je opisano na sliki, tenzorje lahko označimo kot n-dimenzionalno matriko kar nam omogoča predstavitev podatkov v kompleksnih dimenzijah. Vsako dimenzijo lahko razumemo kot drugačno lastnost podatkov v globokem učenju. To pomeni, da lahko tenzorji postanejo precej zapleteni, ko gre za kompleksne nabore podatkov z veliko funkcijami.
Ko enkrat vemo, kaj so Tensorji, mislim, da je zelo enostavno ugotoviti, kaj se dogaja v TensorFlowu. Ti izrazi pomenijo, kako se lahko tenzorji ali funkcije pretakajo v naborih podatkov, da ustvarijo dragocene rezultate, ko z njimi izvajamo različne operacije.
Razumevanje TensorFlow s konstantami
Tako kot beremo zgoraj, nam TensorFlow omogoča izvajanje algoritmov strojnega učenja na Tensorjih, da dobimo dragocene rezultate. S tehnologijo TensorFlow je načrtovanje in usposabljanje modelov globokega učenja neposredno naprej.
TensorFlow prihaja z gradnjo Računski grafi. Grafi za izračun so grafi pretoka podatkov, v katerih so matematične operacije predstavljene kot vozlišča, podatki pa kot robovi med temi vozlišči. Za konkretne vizualizacije napišite zelo preprost delček kode:
uvoz tensorflow kot tfx = tf.konstantno (5)
y = tf.konstantno (6)
z = x * y
natisni (z)
Ko zaženemo ta primer, bomo videli naslednji izhod:
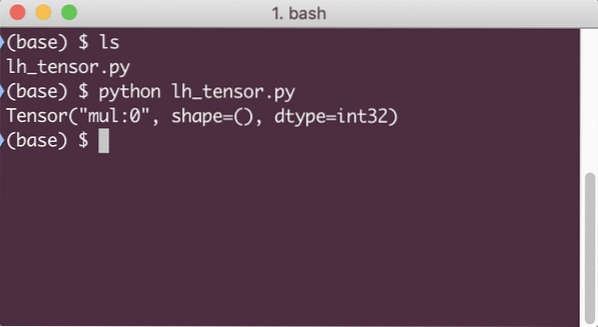
Zakaj je množenje napačno? Nismo pričakovali tega. To se je zgodilo, ker tako ne moremo izvajati operacij s sistemom TensorFlow. Najprej moramo začeti a sejo da računalniški graf deluje,
S Sessions lahko inkapsulirati nadzor delovanja in stanja tenzorjev. To pomeni, da lahko seja shrani tudi rezultat računskega grafa, da lahko ta rezultat posreduje naslednji operaciji v vrstnem redu izvajanja cevovodov. Ustvarimo sejo zdaj, da dobimo pravilen rezultat:
# Začnite s predmetom sejeseja = tf.Seja ()
# Podajte izračun seji in ga shranite
rezultat = seja.teči (z)
# Natisnite rezultat izračuna
natisni (rezultat)
# Zapri sejo
sejo.zapri ()
Tokrat smo dobili sejo in ji zagotovili izračun, ki ga mora zagnati na vozliščih. Ko zaženemo ta primer, bomo videli naslednji izhod:
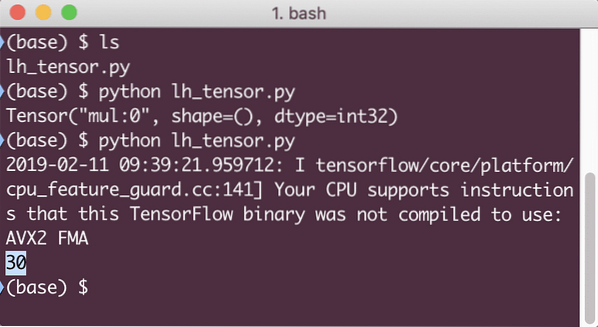
Čeprav smo od TensorFlowa prejeli opozorilo, smo vseeno dobili pravi izhod iz izračuna.
Enodelne tenzorske operacije
Tako kot tisto, kar smo pomnožili z dvema konstantnima tenzorjema v zadnjem primeru, imamo tudi v TensorFlowu številne druge operacije, ki jih je mogoče izvesti na posameznih elementih:
- dodajte
- odštejemo
- pomnožite
- div
- mod
- abs
- negativno
- znak
- kvadrat
- okrogla
- sqrt
- prah
- exp
- log
- največ
- najmanj
- cos
- greh
Operacije z enim elementom pomenijo, da se bodo operacije, tudi če navedete matriko, izvajale na vsakem elementu te matrike. Na primer:
uvoz tensorflow kot tfuvozi numpy kot np
tenzor = np.matrika ([2, 5, 8])
tenzor = tf.convert_to_tensor (tenzor, dtype = tf.float64)
s tf.Seja () kot seja:
natis (seja.teči (tf.cos (tenzor)))
Ko zaženemo ta primer, bomo videli naslednji izhod:
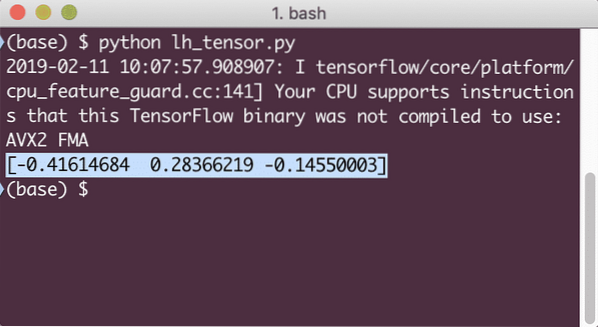
Tu smo razumeli dva pomembna koncepta:
- Vsako matriko NumPy lahko s pomočjo funkcije convert_to_tensor enostavno pretvorite v tenzor
- Operacija je bila izvedena za vsak element matrike NumPy
Ograde in spremenljivke
V enem od prejšnjih razdelkov smo preučili, kako lahko uporabimo konstante Tensorflow za izdelavo računskih grafov. Toda TensorFlow nam omogoča tudi, da vnesemo vhodne podatke med izvajanjem, tako da je lahko računski graf dinamične narave. To je mogoče s pomočjo ograd in spremenljivk.
Dejansko rezervoarji ne vsebujejo nobenih podatkov in morajo med izvajanjem zagotoviti veljavne vnose in, kot je bilo pričakovano, bodo brez vnosa ustvarili napako.
Omejitev lahko označimo kot dogovor na grafu, ki bo zagotovo zagotovil vnos med izvajanjem. Tu je primer ograd:
uvoz tensorflow kot tf# Dve ogradici
x = tf. nadomestni znak (tf.float32)
y = tf. nadomestni znak (tf.float32)
# Dodelitev operacije množenja w.r.t. a & b za vozlišče mul
z = x * y
# Ustvari sejo
seja = tf.Seja ()
# Vrednosti prehoda za platoje
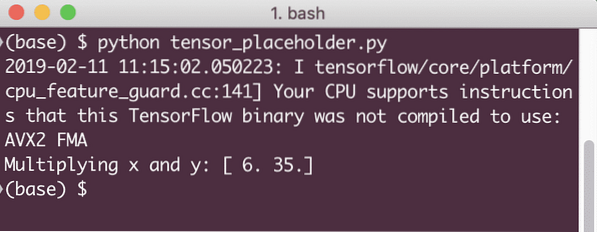
rezultat = seja.zaženi (z, x: [2, 5], y: [3, 7])
print ('Množenje x in y:', rezultat)
Ko zaženemo ta primer, bomo videli naslednji izhod:
Zdaj, ko imamo znanje o ogradicah, si poglejmo spremenljivke. Vemo, da se lahko enačba sčasoma spremeni za enak nabor vhodov. Ko torej treniramo spremenljivko modela, lahko sčasoma spremeni svoje vedenje. V tem primeru nam spremenljivka omogoča, da v svoj računski graf dodamo te vadljive parametre. Spremenljivko lahko definirate na naslednji način:
x = tf.Spremenljivka ([5.2], dtype = tf.float32)V zgornji enačbi je x spremenljivka, ki ima začetno vrednost in vrsto podatkov. Če podatkovnega tipa ne zagotovimo, bo TensorFlow sklepal z njegovo začetno vrednostjo. Glejte podatkovne vrste TensorFlow tukaj.
Za razliko od konstante moramo poklicati funkcijo Python, da inicializiramo vse spremenljivke grafa:
init = tf.global_variables_initializer ()sejo.teči (init)
Zaženite zgornjo funkcijo TensorFlow, preden uporabimo naš graf.
Linearna regresija s TensorFlow
Linearna regresija je eden najpogostejših algoritmov, ki se uporablja za vzpostavitev razmerja v danih neprekinjenih podatkih. To razmerje med koordinatnima točkama, recimo x in y, se imenuje a hipotezo. Ko govorimo o linearni regresiji, je hipoteza ravna črta:
y = mx + cTu je m naklon črte, tu pa predstavlja vektor uteži. c je konstantni koeficient (presek y) in tukaj predstavlja Pristranskost. Teža in pristranskost se imenuje parametrov modela.
Linearne regresije nam omogočajo, da vrednosti teže in pristranskosti ocenimo tako, da imamo najmanj stroškovna funkcija. Končno je x neodvisna spremenljivka v enačbi, y pa odvisna spremenljivka. Zdaj pa začnimo graditi linearni model v TensorFlowu s preprostim delčkom kode, ki ga bomo razložili:
uvoz tensorflow kot tf# Spremenljivke za naklon parametra (W) z začetno vrednostjo 1.1
W = tf.Spremenljivka ([1.1], tf.float32)
# Spremenljivka za pristranskost (b) z začetno vrednostjo -1.1
b = tf.Spremenljivka ([- 1.1], tf.float32)
# Ograde za zagotavljanje vhodne ali neodvisne spremenljivke, označene z x
x = tf.nadomestni znak (tf.float32)
# Enačba premice ali linearna regresija
linearni_model = Š * x + b
# Inicializacija vseh spremenljivk
seja = tf.Seja ()
init = tf.global_variables_initializer ()
sejo.teči (init)
# Izvedite regresijski model
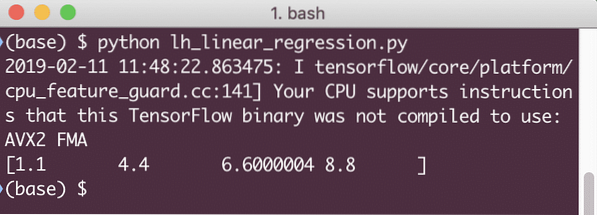
natis (seja.zaženi (linearni_model x: [2, 5, 7, 9])))
Tukaj smo storili tisto, kar smo že razložili, povzemimo tukaj:
- Začeli smo z uvozom TensorFlow v naš skript
- Ustvarite nekaj spremenljivk, ki bodo predstavljale težo vektorja in pristranskost parametra
- Za predstavljanje vnosa bo potreben nadomestni znak, x
- Predstavljajo linearni model
- Inicializirajte vse vrednosti, potrebne za model
Ko zaženemo ta primer, bomo videli naslednji izhod:
Preprost delček kode ponuja samo osnovno idejo o tem, kako lahko zgradimo regresijski model. Toda za dokončanje modela, ki smo ga zgradili, moramo narediti še nekaj korakov:
- Naš model moramo narediti samoizobraževalnega, da bo lahko ustvaril rezultate za kateri koli vložek
- Izhod, ki ga zagotavlja model, moramo potrditi s primerjavo s pričakovanim izhodom za dani x
Funkcija izgube in validacija modela
Za potrditev modela moramo izmeriti, kako odstopa tokovna izhodna moč od pričakovane. Obstajajo različne funkcije izgub, ki jih lahko tukaj uporabimo za preverjanje, vendar bomo preučili eno najpogostejših metod, Vsota napak na kvadrat ali SSE.
Enačba za SSE je podana kot:
E = 1/2 * (t - y) 2Tukaj:
- E = povprečna napaka na kvadrat
- t = prejeti izhod
- y = pričakovani izhod
- t - y = Napaka
Zdaj zapišimo delček kode v nadaljevanju do zadnjega delčka, da odraža vrednost izgube:
y = tf.nadomestni znak (tf.float32)napaka = linearni_model - y
napake kvadrata = tf.kvadrat (napaka)
izguba = tf.znižaj_sum (kvadratne_ napake)
natis (seja.tek (izguba, x: [2, 5, 7, 9], y: [2, 4, 6, 8]))
Ko zaženemo ta primer, bomo videli naslednji izhod:
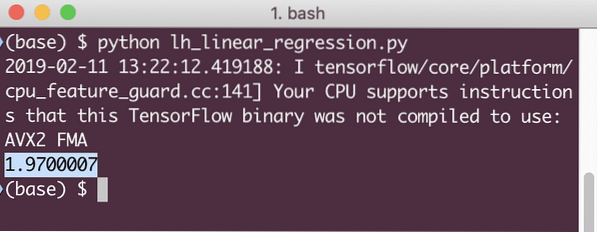
Jasno je, da je vrednost izgube pri danem modelu linearne regresije zelo nizka.
Zaključek
V tej lekciji smo si ogledali enega najbolj priljubljenih paketov za globoko učenje in strojno učenje, TensorFlow. Izdelali smo tudi model linearne regresije, ki je imel zelo visoko natančnost.

