pip namestite BeautifulSoup4
Če želite preveriti, ali je bila namestitev uspešna, aktivirajte interaktivno lupino Python in uvozite BeautifulSoup. Če se ne prikaže nobena napaka, pomeni, da je šlo vse v redu. Če tega ne veste, vnesite naslednje ukaze v terminal.
$ pythonPython 3.5.2 (privzeto, 14. september 2017, 22:51:06)
[GCC 5.4.0 20160609] na Linuxu
Za več informacij vnesite "pomoč", "avtorske pravice", "dobropisi" ali "licenca".
>>> uvozi bs4
Za delo s knjižnico BeautifulSoup morate vnesti html. Pri delu s pravimi spletnimi mesti lahko s pomočjo knjižnice zahtev dobite html spletne strani. Namestitev in uporaba knjižnice zahtev presega obseg tega članka, vendar bi se lahko znašli po dokumentaciji, ki je precej enostavna za uporabo. V tem članku bomo preprosto uporabili html v nizu python, ki bi ga poklicali html.
html = "" "[e-pošta zaščitena]
pparkerworks.com
"" "
Za uporabo beautifulsoup ga uvozimo v kodo s spodnjo kodo:
iz bs4 uvozi BeautifulSoupTo bi uvedlo BeautifulSoup v naš imenski prostor in ga lahko uporabimo pri razčlenjevanju našega niza.
juha = BeautifulSoup (html, "lxml")Zdaj, juha je objekt BeautifulSoup tipa bs4.BeautifulSoup in lahko opravimo vse operacije BeautifulSoup na juhaspremenljivka.
Oglejmo si nekaj stvari, ki jih lahko zdaj naredimo z BeautifulSoup.
NAROČITEV GRADNEGA, LEPEGA
Ko BeautifulSoup razčleni html, običajno ni v najboljših oblikah. Razmiki so precej grozni. Oznake je težko najti. Tu je slika, ki prikazuje, kako bi izgledali, ko natisnete juha:
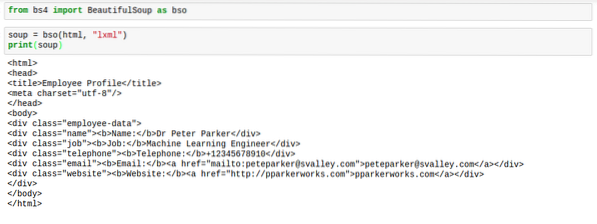
Vendar za to obstaja rešitev. Rešitev daje html popoln razmik, zaradi česar so stvari videti dobro. Ta rešitev se zasluženo imenuje „polepšati“.
Resda te funkcije morda ne boste mogli uporabljati večino časa; vendar včasih morda nimate dostopa do orodja za pregled elementov spletnega brskalnika. V tistih časih omejenih virov bi bila metoda lepljenja zelo koristna.
Tukaj je, kako ga uporabljate:
juha.prettify ()Oznake bi bile videti pravilno razporejene, tako kot na spodnji sliki:
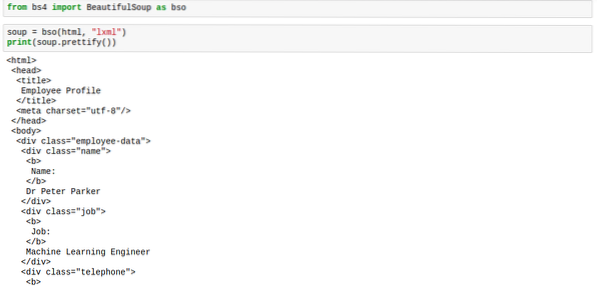
Ko na juho uporabite način prettify, rezultat ni več tip bs4.BeautifulSoup. Rezultat je zdaj vnesite 'unicode'. To pomeni, da na njej ne morete uporabljati drugih metod BeautifulSoup, vendar sama juha ne vpliva, zato smo na varnem.
ISKANJE NAŠIH PRILJUBLJENIH OZNAK
HTML je sestavljen iz oznak. V njih shrani vse svoje podatke, sredi vsega nereda pa ležijo podatki, ki jih potrebujemo. V bistvu to pomeni, da ko najdemo prave oznake, lahko dobimo tisto, kar potrebujemo.
Torej, kako najti prave oznake? Uporabljamo metode BeautifulSoup find in find_all.
Evo, kako delujejo:
The najti metoda poišče prvo oznako s potrebnim imenom in vrne objekt tipa bs4.element.Oznaka.
The find_all metoda po drugi strani poišče vse oznake z zahtevanim imenom oznake in jih vrne kot seznam vrste bs4.element.ResultSet. Vsi elementi na seznamu so vrste bs4.element.Oznaka, tako da lahko izvedemo indeksiranje na seznamu in nadaljujemo s čudovitim raziskovanjem juhe.
Poglejmo nekaj kode. Poiščimo vse oznake div:
juha.najdi (»div«)Dobili bi naslednji rezultat:
Če preverite spremenljivko html, boste opazili, da je to prva oznaka div.
juha.find_all ("div")Dobili bi naslednji rezultat:
[[e-pošta zaščitena]
pparkerworks.com
Vrne seznam. Če želite na primer tretjo oznako div, zaženite naslednjo kodo:
juha.find_all ("div") [2]Vrnilo bi naslednje:
UGOTAVLJANJE ATRIBUTOV NAŠIH PRILJUBLJENIH OZNAK
Zdaj, ko smo videli, kako priti do svojih najljubših oznak, pa kako dobiti njihove atribute?
Morda v tem trenutku razmišljate: »Za kaj potrebujemo lastnosti?“. No, velikokrat bomo večino podatkov, ki jih potrebujemo, predstavljali e-poštni naslovi in spletna mesta. Tovrstni podatki so običajno hiperpovezani na spletnih straneh, povezave pa so v atributu „href“.
Ko izvlečemo potrebno oznako z uporabo metod find ali find_all, lahko z uporabo uporabimo atribute attrs. To bi vrnilo slovar atributa in njegove vrednosti.
Če želimo na primer dobiti atribut e-pošte, dobimo datoteko oznake, ki obkroža potrebne informacije, in naredite naslednje.
juha.find_all ("a") [0].attrsKar bi vrnilo naslednji rezultat:
'href': 'mailto: [email protected]'Enako za atribut spletnega mesta.
juha.find_all ("a") [1].attrsKar bi vrnilo naslednji rezultat:
'href': 'http: // pparkerworks.com'Vrnjene vrednosti so slovarji in za pridobitev ključev in vrednosti je mogoče uporabiti običajno sintakso slovarja.
OGLEDIMO STARŠA IN OTROKE
Oznake so povsod. Včasih želimo vedeti, kaj so otroške oznake in kaj nadrejena oznaka.
Če še ne veste, kaj je nadrejena in podrejena oznaka, zadostuje ta kratka razlaga: nadrejena oznaka je neposredna zunanja oznaka, podrejena pa neposredna notranja oznaka zadevne oznake.
Če pogledamo naš html, je oznaka telesa nadrejena oznaka vseh oznak div. Krepka oznaka in sidrna oznaka sta tudi podrejeni oznaki div, kjer je to primerno, saj vse oznake div nimajo sidrnih oznak.
Tako lahko do starševske oznake dostopamo s klicem findParent metoda.
juha.najdi ("div").findParent ()To bi vrnilo celotno oznako telesa:
[e-pošta zaščitena]
pparkerworks.com
Če želimo dobiti otroško oznako četrte oznake div, pokličemo findChildren metoda:
juha.find_all ("div") [4].findChildren ()Vrne naslednje:
[Spletna stran:, pparkerworks.com]KAJ JE V NAS ZA NAS?
Pri brskanju po spletnih straneh ne vidimo povsod na zaslonu oznak. Vse, kar vidimo, je vsebina različnih oznak. Kaj pa, če želimo vsebino oznake, ne da bi zaradi vseh kotnih oklepajev življenje neprijetno? To ni težko, poklicali bi le get_text na oznaki po izbiri in v oznako dobimo besedilo in če ima oznaka druge oznake, dobi tudi njihove besedilne vrednosti.
Tu je primer:
juha.najdi ("telo").get_text ()To vrne vse besedilne vrednosti v oznaki telesa:
Ime: dr. Peter ParkerSlužba: inženir strojnega učenja
Telefon: +12345678910
E-pošta: [e-pošta zaščitena]
Spletno mesto: pparkerworks.com
ZAKLJUČEK
To imamo za ta članek. Še vedno pa obstajajo še druge zanimive stvari, ki jih je mogoče narediti z beautifulsoup. Lahko si ogledate dokumentacijo ali uporabite dir (BeautfulSoup) na interaktivni lupini, da si ogledate seznam operacij, ki jih je mogoče izvesti na objektu BeautifulSoup. To je vse od mene danes, dokler spet ne pišem.


