Če želite razumeti koncept iskanja po celotnem besedilu, se morate spomniti znanja o iskanju vzorcev s pomočjo ključne besede LIKE. Predpostavimo torej tabelo 'oseba' v 'testu' zbirke podatkov z naslednjimi zapisi.
>> IZBERI * OD osebe;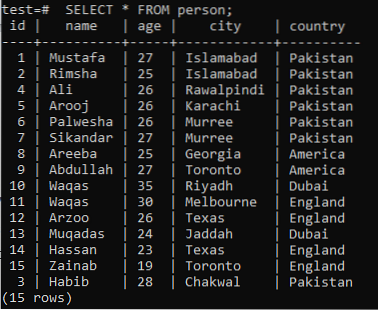
Predpostavimo, da želite pridobiti zapise te tabele, kjer ima stolpec 'ime' znak 'i' v kateri koli vrednosti. Med uporabo stavka LIKE v ukazni lupini poskusite s spodnjo poizvedbo SELECT. Iz spodnjega izhoda lahko vidite, da imamo v stolpcu "ime" le 5 zapisov za ta znak 'i'.
>> IZBERI * OD osebe, KJER ime KOT KOT '% i%';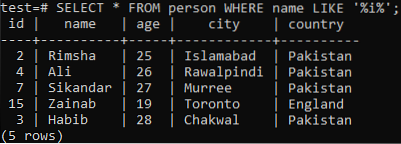
Uporaba zdravila Tvsector:
Včasih za hitro iskanje vzorcev ni koristno uporabiti ključne besede LIKE, čeprav je beseda tam. Morda bi razmislili o uporabi standardnih izrazov, in čeprav je to izvedljiva alternativa, so regularni izrazi močni in počasni. Obstoj postopkovnega vektorja za celotne besede v besedilu in njihov besedni opis je veliko učinkovitejši način za reševanje te težave. Koncept popolnega iskanja besedila in podatkovni tip tsvector je bil ustvarjen za odziv nanj. V PostgreSQL obstajata dve metodi, ki počneta točno tisto, kar si želimo:
- To_tvsector: Uporablja se za sestavljanje seznama žetonov (ts pomeni za "iskanje besedila").
- To_tsquery: Uporablja se za iskanje vektorjev za pojavnost določenih izrazov ali besednih zvez.
Primer 01:
Začnimo s preprosto ponazoritvijo ustvarjanja vektorja. Recimo, da želite narediti vektor za vrvico: »Nekateri imajo s pravilno ščetkanjem kodraste rjave lase.". Torej morate napisati funkcijo to_tvsector () skupaj s tem stavkom v oklepajih poizvedbe SELECT, kot je priloženo spodaj. Iz spodnjega izhoda lahko vidite, da bi povzročil vektor sklicev (položaji datotek) za vsak žeton in tudi tam, kjer so izrazi z malo konteksta, na primer članki () in vezniki (in, ali), namerno prezrti.
>> SELECT to_tsvector ('Nekateri imajo s pravilno ščetkanjem kodraste rjave dlake');
Primer 02:
Predpostavimo, da imate dva dokumenta z nekaj podatki v obeh. Za shranjevanje teh podatkov bomo zdaj uporabili pravi primer ustvarjanja žetonov. Predpostavimo, da ste ustvarili tabelo 'Podatki' v svoji bazi podatkov 'test' z nekaj stolpci v njej z uporabo spodnje poizvedbe CREATE TABLE. Ne pozabite v njem ustvariti stolpca tipa TVSECTOR z imenom 'žeton'. Iz spodnjega izhoda si lahko ogledate tabelo, ki je bila ustvarjena.
>> USTVARI PODATKE (Id SERIJSKI PRIMARNI KLJUČ, BESEDILO z informacijami, žeton TSVECTOR);
Zdaj se moramo obrniti na to, da v tej tabeli dodamo celotne podatke obeh dokumentov. Zato poskusite spodnji ukaz INSERT v lupini ukazne vrstice, da to storite. Na koncu so bili zapisi iz obeh dokumentov uspešno dodani v tabelo 'Podatki'.
>> VSTAVITE V VREDNOSTI podatkov (informacij) ('Dve napaki nikoli ne moreta popraviti ene.'), (' On je tisti, ki lahko igra nogomet.'), (' Ali lahko igram vlogo pri tem?'), (' Bolečine v človeku ni mogoče razumeti '), (' V svoje življenje prinesite breskev);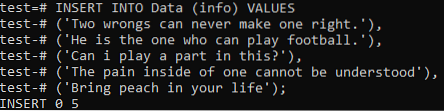
Zdaj morate kolonizirati stolpec obeh dokumentov z njihovim določenim vektorjem. Preprosta poizvedba UPDATE bo za vsako datoteko zapolnila stolpec žetonov z ustreznim vektorjem. Torej morate v ukazni lupini izvesti spodnjo poizvedbo. Rezultat kaže, da je bila posodobitev končno izvedena.
>> UPDATE Data f1 SET token = to_tsvector (f1.info) IZ podatkov f2;
Zdaj, ko imamo vse na mestu, se s skeniranjem vrnimo na našo ponazoritev »lahko ena«. Kot prej rečeno, da to_tsquery z operaterjem AND ne razlikuje med lokacijami datotek v datotekah, kot je razvidno iz spodaj navedenega izhoda.
>> SELECT ID, info FROM Data WHERE žeton @@ to_tsquery ('can & one');
Primer 04:
Da bi našli besede, ki so "zraven", bomo poskusili isto poizvedbo z<->'operater. Sprememba je prikazana v spodnjem izhodu.
>> SELECT ID, info FROM Data WHERE žeton @@ to_tsquery ('can <-> ena ');
Tu je primer nobene neposredne besede poleg druge.
>> SELECT ID, info FROM Data WHERE žeton @@ to_tsquery ('one <-> bolečina ');
Primer 05:
Besede, ki se ne nahajajo tik ob drugi, bomo našli s pomočjo številke v operatorju razdalje za sklicevanje na razdaljo. Blizina med »prinesi« in »življenje« je od prikazane slike oddaljena samo 4 besede.
>> SELECT * FROM Data WHERE žeton @@ to_tsquery ('prinesi <4> življenje ');
Za preverjanje bližine med besedami za skoraj 5 besed je priloženo spodaj.
>> SELECT * FROM Data WHERE žeton @@ to_tsquery ('narobe <5> prav');
Zaključek:
Na koncu ste naredili vse preproste in zapletene primere iskanja po celotnem besedilu z uporabo operatorjev in funkcij To_tvsector in to_tsquery.


