Na primer, podjetje lahko zažene mehanizem za analizo besedila, ki obdeluje tvite o svojem podjetju, pri čemer omenja ime podjetja, lokacijo, postopek in analizira čustva, povezana s tem tvitom. Pravilne ukrepe je mogoče sprejeti hitreje, če to podjetje spozna na naraščajoče negativne tvite za to podjetje na določeni lokaciji, da se reši pred napako ali čim drugim. Še en pogost primer bo za Youtube. Skrbniki in moderatorji Youtube spoznajo učinek videoposnetka glede na vrsto komentarjev na videoposnetek ali sporočil v video klepetu. To jim bo pomagalo najti neprimerno vsebino na spletnem mestu veliko hitreje, ker so zdaj izkoreninili ročno delo in zaposlili avtomatizirane pametne robote za analizo besedila.
V tej lekciji bomo s pomočjo knjižnice NLTK v Pythonu preučili nekatere koncepte, povezane z analizo besedila. Nekateri od teh konceptov bodo vključevali:
- Tokenizacija, kako del besedila razbiti na besede, stavke
- Izogibanje besed za zaustavitev, ki temeljijo na angleškem jeziku
- Izvajanje matičnih besed in lematizacije na delu besedila
- Prepoznavanje žetonov, ki jih je treba analizirati
NLP bo v tej lekciji osredotočen na glavno področje, saj je uporaben za velike scenarije iz resničnega življenja, kjer lahko reši velike in ključne probleme. Če menite, da se to sliši zapleteno, je res tako, vendar je koncepte enako enostavno razumeti, če primere preizkušate drug ob drugem. Za začetek namestite NLTK na vaš računalnik.
Namestitev NLTK
Samo opomba pred začetkom, za to lekcijo lahko uporabite navidezno okolje, ki ga lahko naredimo z naslednjim ukazom:
python -m virtualenv nltkvir nltk / bin / activate
Ko je navidezno okolje aktivno, lahko v virtualno env namestite knjižnico NLTK, tako da lahko izvajamo primere, ki jih ustvarimo naslednji:
pip namestite nltkV tej lekciji bomo uporabili Anacondo in Jupyter. Če ga želite namestiti na svoj računalnik, si oglejte lekcijo, ki opisuje »Kako namestiti Anaconda Python na Ubuntu 18.04 LTS «in delite svoje povratne informacije, če imate kakršne koli težave. Če želite namestiti NLTK z Anacondo, v terminalu iz Anaconde uporabite naslednji ukaz:
conda install -c anaconda nltkNekaj takega vidimo, ko izvršimo zgornji ukaz:
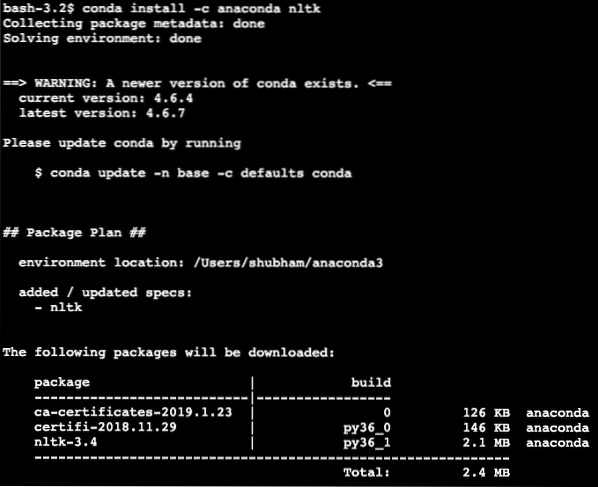
Ko so vsi potrebni paketi nameščeni in končani, lahko začnemo z uporabo knjižnice NLTK z naslednjim izjavo o uvozu:
uvozi nltkZačnimo z osnovnimi primeri NLTK zdaj, ko imamo nameščene pakete predpogojev.
Tokenizacija
Začeli bomo s tokenizacijo, ki je prvi korak pri izvajanju analize besedila. Žeton je lahko kateri koli manjši del besedila, ki ga je mogoče analizirati. Z NLTK lahko izvedemo dve vrsti tokenizacije:
- Tokenizacija stavkov
- Besedna tokenizacija
Lahko ugibate, kaj se zgodi na vsaki tokenizaciji, zato se potopimo v primere kode.
Tokenizacija stavkov
Kot že ime pove, Senkence Tokenizers deli besedilo na stavke. Preizkusimo preprost delček kode za isto, kjer uporabimo besedilo, ki smo ga izbrali iz vadnice Apache Kafka. Izvedli bomo potreben uvoz
uvozi nltkiz nltk.sl Uvozi tokenize
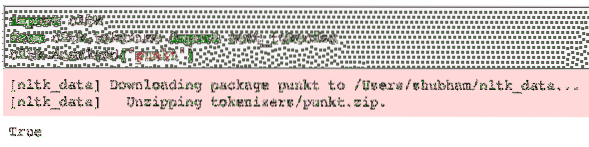
Upoštevajte, da se boste morda soočili z napako zaradi manjkajoče odvisnosti za klicano nltk punkt. Takoj za uvozom v program dodajte naslednjo vrstico, da se izognete opozorilom:
nltk.prenesi ('punkt')Zame je dal naslednji rezultat:
Nato uporabimo stavčni tokenizer, ki smo ga uvozili:
text = "" "Tema v Kafki je nekaj, kamor se pošlje sporočilo. Potrošnikaplikacije, ki jih ta tema zanima, potegne sporočilo v to
temo in lahko s temi podatki stori karkoli. Do določenega časa, poljubno število
potrošniške aplikacije lahko to sporočilo povlečejo poljubno številokrat."" "
stavki = sent_tokenize (besedilo)
tisk (stavki)
Nekaj takega vidimo, ko izvedemo zgornji skript:

Po pričakovanjih je bilo besedilo pravilno razvrščeno v stavke.
Besedna tokenizacija
Kot že ime pove, Word Tokenizers del besedila razdeli na besede. Preizkusimo preprost delček kode za isto z istim besedilom kot prejšnji primer:
iz nltk.tokenize uvoz word_tokenizewords = word_tokenize (besedilo)
tisk (besede)
Nekaj takega vidimo, ko izvedemo zgornji skript:

Po pričakovanjih je bilo besedilo pravilno razvrščeno v besede.
Porazdelitev frekvence
Zdaj, ko smo razbili besedilo, lahko izračunamo tudi pogostost vsake besede v besedilu, ki smo ga uporabili. Z NLTK je zelo enostavno, tukaj je delček kode, ki ga uporabljamo:
iz nltk.verjetnost uvoza FreqDistdistribucija = FreqDist (besede)
tisk (distribucija)
Nekaj takega vidimo, ko izvedemo zgornji skript:

Nato lahko v besedilu najdemo najpogostejše besede s preprosto funkcijo, ki sprejme prikazano število besed:
# Najpogostejše besededistribucija.najbolj pogosto (2)
Nekaj takega vidimo, ko izvedemo zgornji skript:

Na koncu lahko naredimo ploskev porazdelitve frekvence, da razjasnimo besede in njihovo štetje v danem besedilu ter jasno razumemo razporeditev besed:

Stopwords
Tako kot pri klicu z drugo osebo prek klica tudi med klicem nastane nekaj hrupa, ki je nezaželena informacija. Na enak način tudi besedilo iz resničnega sveta vsebuje šum, ki ga imenujemo Stopwords. Štoparice se lahko razlikujejo od jezika do jezika, vendar jih je mogoče zlahka prepoznati. Nekatere vstopne besede v angleškem jeziku so lahko - so, so, a, the, itd.
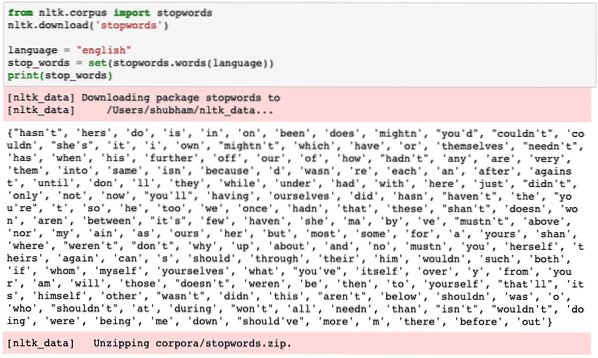
Besede, ki jih NLTK za angleški jezik šteje za gesla, si lahko ogledamo z naslednjim delčkom kode:
iz nltk.zapornice za uvoz korpusanltk.prenos ('stopwords')
language = "angleščina"
stop_words = set (stopwords.besede (jezik))
tiskanje (stop_words)
Ker je nabor besed za zaustavitev lahko velik, je shranjen kot ločen nabor podatkov, ki ga lahko prenesete z NLTK, kot smo prikazali zgoraj. Nekaj takega vidimo, ko izvedemo zgornji skript:
Če želite natančno analizirati besedilo, ki ste ga prejeli, je treba te besedne besede ustaviti iz besedila. Odstranimo besedo stop iz naših besedilnih žetonov:
filtered_words = []za besedo v besedah:
če besede ni v stop_words:
filtrirane_besede.dodaj (beseda)
filtrirane_besede
Nekaj takega vidimo, ko izvedemo zgornji skript:

Besedno zaznamovanje
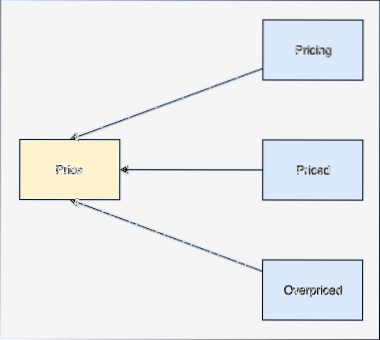
Steblo besede je osnova te besede. Na primer:
Nastopili bomo na podlagi filtriranih besed, iz katerih smo v zadnjem poglavju odstranili zaustavitvene besede. Zapišemo preprost delček kode, kjer za izvedbo operacije uporabimo NLTK-jev stemmer:
iz nltk.uvoz stebla PorterStemmerps = PorterStemmer ()
stemmed_words = []
za besedo v filtered_words:
stemmed_words.priloži (ps.deblo (beseda))
print ("Zarečena stavek:", izvorne_besede)
Nekaj takega vidimo, ko izvedemo zgornji skript:

Označevanje POS
Naslednji korak v besedilni analizi je po tem, ko vsaka beseda opredeli in razvrsti glede na njeno vrednost, tj.e. če je vsaka beseda samostalnik ali glagol ali kaj drugega. To se imenuje del označevanja govora. Izvedimo označevanje POS zdaj:
žetoni = nltk.word_tokenize (stavki [0])tisk (žetoni)
Nekaj takega vidimo, ko izvedemo zgornji skript:

Zdaj lahko izvedemo označevanje, za kar bomo morali prenesti drug nabor podatkov, da bomo prepoznali pravilne oznake:
nltk.prenos ('povprečen_perceptron_tagger')nltk.pos_tag (žetoni)
Tu je rezultat označevanja:
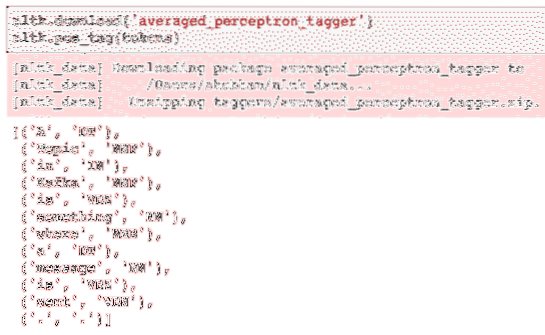
Zdaj, ko smo končno prepoznali označene besede, je to nabor podatkov, na katerem lahko opravimo analizo sentimenta, da prepoznamo čustva za stavkom.
Zaključek
V tej lekciji smo preučili odličen naravni jezikovni paket NLTK, ki nam omogoča, da z nestrukturiranimi besedilnimi podatki prepoznamo morebitne zaustavitvene besede in izvedemo globlje analize s pripravo ostrega nabora podatkov za analizo besedila s knjižnicami, kot je sklearn.
Poiščite vso izvorno kodo, uporabljeno v tej lekciji, na Githubu. Prosimo, delite svoje povratne informacije o lekciji na Twitterju z @sbmaggarwal in @LinuxHint.


