Koda tega spletnega dnevnika je skupaj z naborom podatkov na voljo na naslednji povezavi https: // github.com / shekharpandey89 / k-pomeni
Skupina K-Means je nenadzorovani algoritem strojnega učenja. Če primerjamo nenadzorovani algoritem združevanja v skupine K-Means z nadzorovanim algoritmom, modela ni treba usposobiti z označenimi podatki. Algoritem K-Means se uporablja za razvrščanje ali razvrščanje različnih predmetov na podlagi njihovih lastnosti ali lastnosti v K število skupin. Tu je K celoštevilsko število. K-Means izračuna razdaljo (z uporabo formule razdalje) in nato poišče najmanjšo razdaljo med podatkovnimi točkami in centroidno skupino za razvrščanje podatkov.
Razumejmo K-sredstva na majhnem primeru z uporabo 4 predmetov, vsak objekt pa ima 2 atributa.
| ObjectsName | Atribut_X | Atribut_Y |
|---|---|---|
| M1 | 1 | 1 |
| M2 | 2 | 1 |
| M3 | 4 | 3 |
| M4 | 5 | 4 |
K-pomeni za reševanje numeričnega primera:
Za rešitev zgornjega numeričnega problema s pomočjo K-Means moramo slediti naslednjim korakom:
Algoritem K-Means je zelo preprost. Najprej moramo izbrati poljubno naključno število K in nato izbrati centroide ali središče skupin. Za izbiro centroidov lahko za inicializacijo izberemo poljubno število predmetov (odvisno od vrednosti K).
Osnovni koraki algoritma K-Means so naslednji:
- Še naprej teče, dokler se noben predmet ne premakne s svojih centroidov (stabilno).
- Nekaj centroidov najprej izberemo naključno.
- Nato določimo razdaljo med vsakim predmetom in centroidi.
- Združevanje predmetov na podlagi najmanjše razdalje.
Torej, vsak objekt ima dve točki kot X in Y, na prostoru grafa pa predstavljata naslednje:
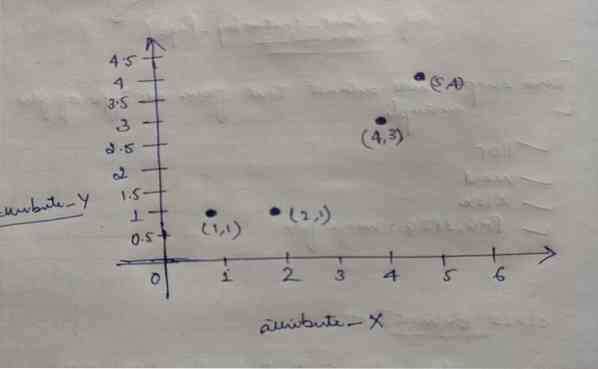
Torej na začetku izberemo vrednost K = 2 kot naključno za rešitev zgoraj navedene težave.
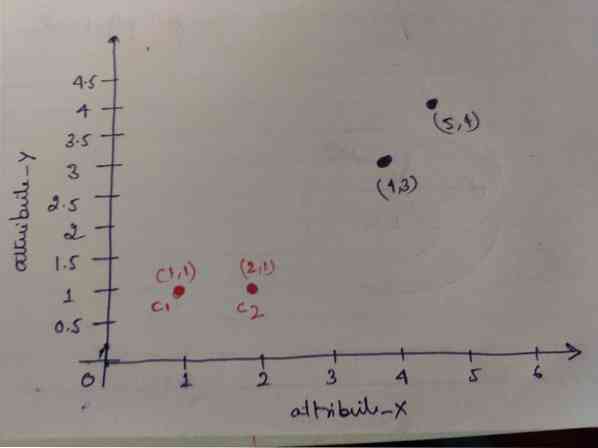
1. korak: Sprva za središča izberemo prva dva predmeta (1, 1) in (2, 1). Spodnji graf prikazuje enako. Tem centroidom pravimo C1 (1, 1) in C2 (2,1). Tu lahko rečemo, da je C1 skupina_1 in C2 skupina_2.
2. korak: Zdaj bomo izračunali vsako podatkovno točko predmeta do centroidov z uporabo evklidske formule razdalje.
Za izračun razdalje uporabimo naslednjo formulo.

Izračunamo razdaljo od predmetov do centroidov, kot je prikazano na spodnji sliki.

Torej smo izračunali razdaljo točke podatkov vsakega predmeta z zgornjo metodo razdalje in končno dobili matriko razdalje, kot je podana spodaj:
DM_0 =
| 0 | 1 | 3.61 | 5 | C1 = (1,1) grozd1 | skupina_1 |
| 1 | 0 | 2.83 | 4.24 | C2 = (2,1) grozd2 | skupina_2 |
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | X |
| 1 | 1 | 3 | 4 | Y |
Zdaj smo izračunali vrednost razdalje vsakega predmeta za vsak centroid. Na primer, predmetne točke (1,1) imajo vrednost razdalje do c1 0 in c2 1.
Ker iz zgornje matrice razdalje ugotovimo, da ima objekt (1, 1) razdaljo do grozda1 (c1) 0 in do grozda2 (c2) 1. Torej je objekt eden blizu samega grozda1.
Podobno, če preverimo objekt (4, 3), je razdalja do grozda 1 3.61 in grozdu 2 je 2.83. Torej, objekt (4, 3) se bo premaknil v gručo2.
Podobno, če preverite, ali je predmet (2, 1), razdalja do grozda 1 enaka 1, do grozda 2 pa 0. Torej, ta predmet se bo premaknil na cluster2.
Zdaj glede na vrednost razdalje točke razvrščamo v skupine (združevanje objektov).
G_0 =
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | skupina_1 |
| 0 | 1 | 1 | 1 | skupina_2 |
Zdaj glede na vrednost razdalje točke razvrščamo v skupine (združevanje objektov).
In končno, graf bo izgledal kot spodaj po izvedbi združevanja (G_0).
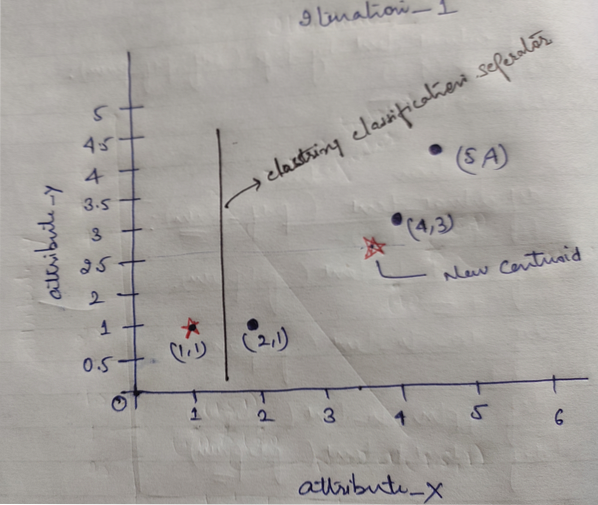
Ponavljanje_1: Zdaj bomo izračunali nove centroide, ko se bodo začetne skupine spremenile zaradi formule razdalje, kot je prikazana v G_0. Torej ima group_1 samo en objekt, zato je njegova vrednost še vedno c1 (1,1), vendar ima group_2 3 predmete, zato je nova vrednost težišča 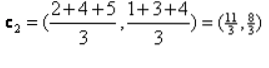
Torej, novi c1 (1,1) in c2 (3.66, 2.66)
Zdaj moramo spet izračunati vso razdaljo do novih centroidov, kot smo izračunali prej.
DM_1 =
| 0 | 1 | 3.61 | 5 | C1 = (1,1) grozd1 | skupina_1 |
| 3.14 | 2.36 | 0.47 | 1.89 | C2 = (3.66,2.66) grozd2 | skupina_2 |
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | X |
| 1 | 1 | 3 | 4 | Y |
Iteration_1 (združevanje objektov): Zdaj ga v imenu novega izračuna matrice razdalje (DM_1) razvrstimo v skladu s tem. Torej premaknemo objekt M2 iz skupine_2 v skupino_1 kot pravilo najmanjše razdalje do centroidov, preostali predmet pa bo enak. Tako bo novo združevanje v skupine, kot spodaj.
G_1 =
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | skupina_1 |
| 0 | 0 | 1 | 1 | skupina_2 |
Zdaj moramo znova izračunati nove centroide, saj imata oba predmeta dve vrednosti.
Torej, novi centroidi bodo 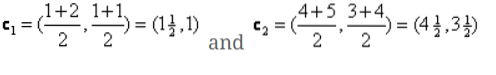
Ko bomo dobili nove centroide, bo združevanje videti kot spodaj:
c1 = (1.5, 1)
c2 = (4.5, 3.5)
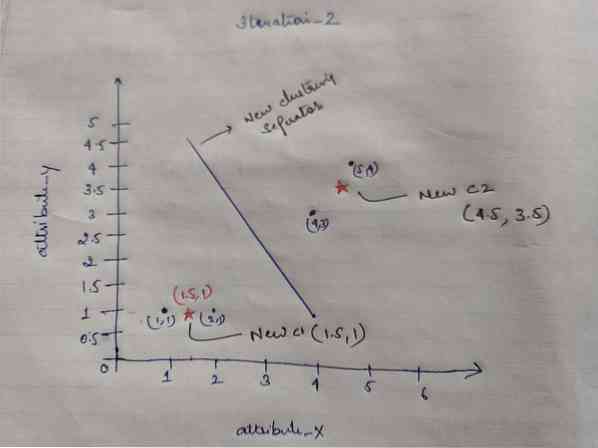
Ponavljanje_2: Ponovimo korak, kjer izračunamo novo razdaljo vsakega predmeta do novih izračunanih centroidov. Po izračunu bomo za iteracijo_2 dobili naslednjo matriko razdalje.
DM_2 =
| 0.5 | 0.5 | 3.20 | 4.61 | C1 = (1.5, 1) grozd1 | skupina_1 |
| 4.30 | 3.54 | 0.71 | 0.71 | C2 = (4.5, 3.5) grozd2 | skupina_2 |
A B C D
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | X |
| 1 | 1 | 3 | 4 | Y |
Spet naloge gručiranja izvajamo na podlagi najmanjše razdalje, kot smo jo prej. Po tem smo dobili matriko grozdenja, ki je enaka G_1.
G_2 =
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | skupina_1 |
| 0 | 0 | 1 | 1 | skupina_2 |
Kot tukaj, G_2 == G_1, tako da nadaljnja ponovitev ni potrebna, in tu se lahko ustavimo.
K-pomeni izvajanje z uporabo Pythona:
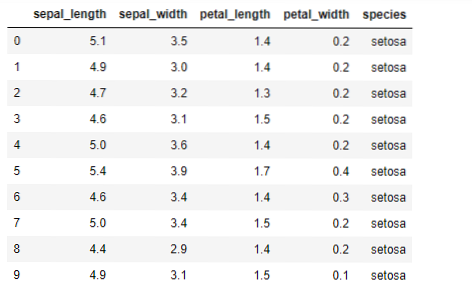
Zdaj bomo v pythonu izvedli algoritem K-pomeni. Za izvajanje K-sredstev bomo uporabili znameniti nabor podatkov Iris, ki je odprtokoden. Ta nabor podatkov ima tri različne razrede. Ta nabor podatkov ima v bistvu štiri lastnosti: Dolžina čašice, širina čašic, dolžina cvetnih listov in širina cvetnih listov. Zadnji stolpec bo povedal ime razreda te vrstice, kot je setosa.
Nabor podatkov je videti spodaj:
Za izvajanje python k-pomeni moramo uvoziti zahtevane knjižnice. Torej iz sklearna uvozimo Pande, Numpy, Matplotlib in tudi KMeans.kot spodaj:

Beremo Iris.Nabor podatkov csv z uporabo metode pande read_csv in bo prikazal 10 najboljših rezultatov z metodo glave.
Zdaj beremo samo tiste značilnosti nabora podatkov, ki smo jih potrebovali za urjenje modela. Torej beremo vse štiri značilnosti naborov podatkov (dolžina ločnice, širina čašic, dolžina cvetnih listov, širina cvetnih listov). Za to smo štiri vrednosti indeksa [0, 1, 2, 3] prenesli v funkcijo iloc podatkovnega okvira pande (df), kot je prikazano spodaj:
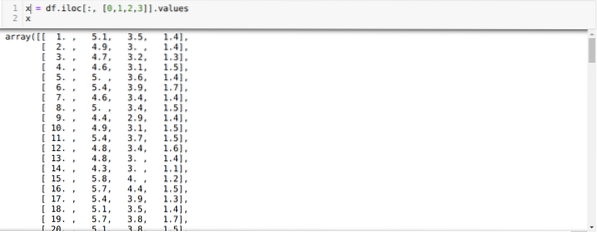
Zdaj naključno izberemo število skupin (K = 5). Ustvarimo predmet razreda K-pomeni in nato svoj nabor podatkov x prilagodimo tistemu za usposabljanje in napovedovanje, kot je prikazano spodaj:
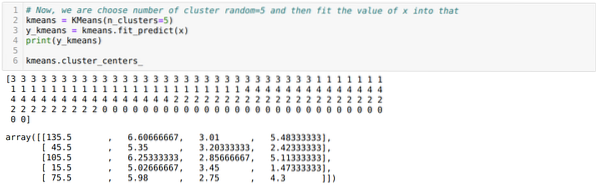
Zdaj bomo vizualizirali svoj model z naključno vrednostjo K = 5. Jasno vidimo pet grozdov, vendar se zdi, da ni natančen, kot je prikazano spodaj.
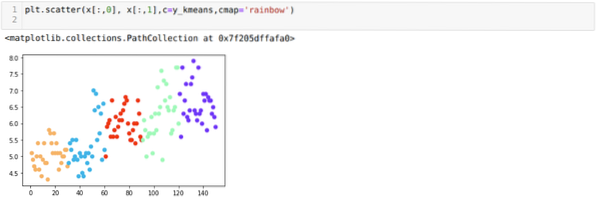
Naslednji korak je torej ugotoviti, ali je bilo število grozdov natančno ali ne. In za to uporabljamo metodo komolca. Metoda komolca se uporablja za ugotavljanje optimalnega števila grozdov za določen nabor podatkov. S to metodo bomo ugotovili, ali je bila vrednost k = 5 pravilna ali ne, saj ne dobimo jasnega združevanja. Po tem gremo na naslednji graf, ki kaže, da vrednost K = 5 ni pravilna, ker optimalna vrednost pade med 3 ali 4.
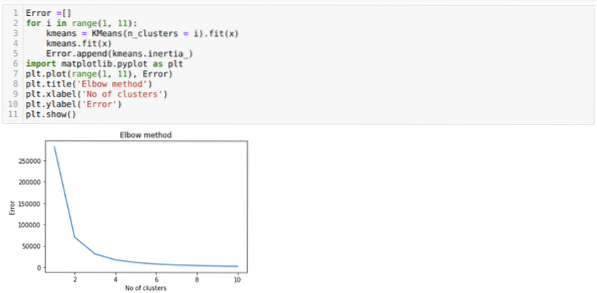
Zdaj bomo znova zagnali zgornjo kodo s številom grozdov K = 4, kot je prikazano spodaj:
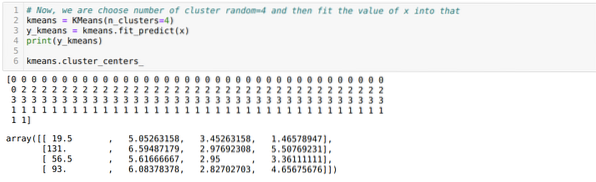
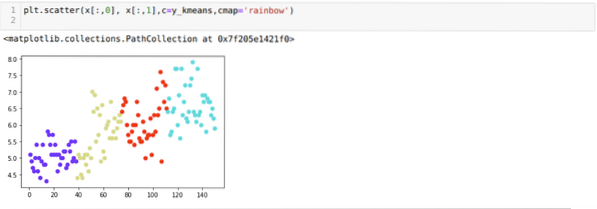
Zdaj bomo vizualizirali zgornje združevanje K = 4 nove gradnje. Spodnji zaslon prikazuje, da se zdaj združevanje izvaja prek k-sredstev.
Zaključek
Torej smo preučevali algoritem K-pomeni tako v numerični kot v python kodi. Videli smo tudi, kako lahko ugotovimo število grozdov za določen nabor podatkov. Včasih metoda komolca ne more dati pravega števila grozdov, zato lahko v tem primeru izberemo več metod.


