To je nadaljevalni članek k prejšnjemu. Pokrili bomo, kako izboljšati poizvedbo, oblikovati bolj zapletena merila iskanja z različnimi parametri in razumeti različne spletne obrazce strani poizvedbe Apache Solr. Razpravljali bomo tudi o tem, kako naknadno obdelati rezultat iskanja z različnimi izhodnimi formati, kot so XML, CSV in JSON.
Poizvedovanje po Apache Solr
Apache Solr je zasnovan kot spletna aplikacija in storitev, ki deluje v ozadju. Rezultat je, da lahko katera koli odjemalska aplikacija komunicira s Solrjem tako, da mu pošilja poizvedbe (poudarek tega članka), manipulira z jedrom dokumenta z dodajanjem, posodabljanjem in brisanjem indeksiranih podatkov ter optimizacijo osnovnih podatkov. Obstajata dve možnosti - prek nadzorne plošče / spletnega vmesnika ali z uporabo API-ja s pošiljanjem ustrezne zahteve.
Običajno je uporabiti prva možnost za namene testiranja in ne za reden dostop. Spodnja slika prikazuje nadzorno ploščo iz uporabniškega vmesnika za upravljanje Apache Solr z različnimi obrazci za poizvedbe v spletnem brskalniku Firefox.
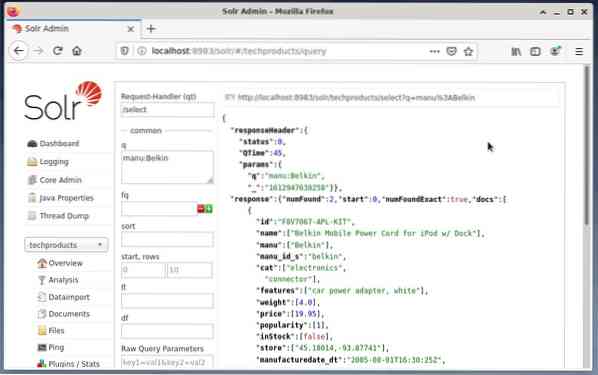
Najprej v meniju pod izbirnim poljem jedra izberite vnos v meniju »Poizvedba«. Nato bo nadzorna plošča prikazala več vnosnih polj, kot sledi:
- Upravljavec zahtev (qt):
Določite, katero vrsto zahteve želite poslati družbi Solr. Izbirate lahko med privzetimi obdelovalci zahtev “/ select” (poizvedba indeksira podatke), “/ update” (posodobi indeksirane podatke) in “/ delete” (odstrani navedene indeksirane podatke) ali samo-definirano. - Poizvedbeni dogodek (q):
Določite imena in vrednosti polj, ki jih želite izbrati. - Filtriraj poizvedbe (fq):
Omejite nabor dokumentov, ki jih je mogoče vrniti, ne da bi to vplivalo na rezultat dokumenta. - Razvrsti (vrstni red):
Določite vrstni red razvrščanja rezultatov poizvedbe naraščajoče ali padajoče - Izhodno okno (začetek in vrstice):
Izhod omejite na določene elemente - Seznam polj (fl):
Informacije, vključene v odgovor na poizvedbo, omejijo na določen seznam polj. - Izhodna oblika (wt):
Določite želeni izhodni format. Privzeta vrednost je JSON.
S klikom na gumb Izvedi poizvedbo zaženete želeno zahtevo. Za praktične primere si oglejte spodaj.
Kot druga možnost, zahtevo lahko pošljete z API-jem. To je zahteva HTTP, ki jo lahko pošlje Apache Solr katera koli aplikacija. Solr obdela zahtevo in vrne odgovor. Poseben primer tega je povezava z Apache Solr prek Java API. To je bilo dodeljeno ločenemu projektu SolrJ [7] - Java API brez potrebe po povezavi HTTP.
Sintaksa poizvedbe
Sintaksa poizvedbe je najbolje opisana v [3] in [5]. Imena različnih parametrov se neposredno ujemajo z imeni vnosnih polj v obrazcih, razloženih zgoraj. Spodnja tabela jih našteva in praktične primere.
Indeks parametrov poizvedbe
| Parameter | Opis | Primer |
|---|---|---|
| q | Glavni parameter poizvedbe Apache Solr - imena polj in vrednosti. Njihove podobnosti ocenjujejo izraze v tem parametru. | Id: 5 avtomobili: * adilla * *: X5 |
| fq | Omejite nabor rezultatov na nadnabojene dokumente, ki se ujemajo s filtrom, na primer določen s pomočjo razčlenjevalnika poizvedb funkcije | model id, model |
| začetek | Odmiki za rezultate strani (začetek). Privzeta vrednost tega parametra je 0. | 5 |
| vrstice | Odmiki za rezultate strani (konec). Vrednost tega parametra je privzeto 10 | 15 |
| razvrsti | Določa seznam polj, ločenih z vejicami, na podlagi katerih bodo razvrščeni rezultati poizvedbe | model asc |
| fl | Določa seznam polj, ki jih je treba vrniti za vse dokumente v naboru rezultatov | model id, model |
| mas | Ta parameter predstavlja vrsto zapisovalnika odzivov, za katerega smo želeli videti rezultat. Vrednost tega je privzeto JSON. | json xml |
Iskanja se izvajajo prek zahteve HTTP GET z nizom poizvedbe v parametru q. Spodnji primeri bodo pojasnili, kako to deluje. V uporabi je curl za pošiljanje poizvedbe Solr, ki je nameščen lokalno.
- Pridobite vse nabore podatkov iz osnovnega avtomobila curl http: // localhost: 8983 / solr / cars / query?q = *: *
- Pridobite vse nabore podatkov iz osrednjih avtomobilov, ki imajo ID 5 curl http: // localhost: 8983 / solr / cars / query?q = id: 5
- Pridobite model polja iz vseh naborov podatkov osnovnih vozil
1. možnost (s pobeglim &): curl http: // localhost: 8983 / solr / cars / query?q = id: * \ & fl = modelMožnost 2 (poizvedba v posameznih kljukicah):
curl 'http: // localhost: 8983 / solr / cars / query?q = id: * & fl = model ' - Pridobite vse nabore podatkov o osnovnih avtomobilih, razvrščenih po ceni v padajočem vrstnem redu, in izpišite samo polja znamke, model in ceno (različica v enojnih kljukicah): curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
razvrsti = cena opis &
fl = znamka, model, cena ' - Pridobite prvih pet naborov podatkov o osnovnih avtomobilih, razvrščenih po ceni v padajočem vrstnem redu, in izpišite samo polja znamke, model in ceno (različica v enojnih kljukicah): curl http: // localhost: 8983 / solr / cars / query - d '
q = *: * &
vrstice = 5 &
razvrsti = cena opis &
fl = znamka, model, cena ' - Pridobite prvih pet naborov podatkov o osnovnih avtomobilih, razvrščenih po cenah v padajočem vrstnem redu, in izpišite polja znamke, model in ceno ter lestvico ustreznosti, samo (različica v enojnih kljukicah): curl http: // localhost: 8983 / solr / avtomobili / poizvedba -d '
q = *: * &
vrstice = 5 &
razvrsti = cena opis &
fl = znamka, model, cena, ocena ' - Vrnite vsa shranjena polja in oceno ustreznosti: curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
fl = *, rezultat '
Poleg tega lahko določite svojega lastnega upravljavca zahtev, da pošlje neobvezne parametre zahteve v razčlenjevalnik poizvedb, da nadzira, katere informacije se vrnejo.
Razčlenjevalniki poizvedb
Apache Solr uporablja tako imenovani razčlenjevalnik poizvedb - komponento, ki prevede vaš iskalni niz v posebna navodila za iskalnik. Razčlenjevalnik poizvedb stoji med vami in dokumentom, ki ga iščete.
Solr prihaja z različnimi vrstami razčlenjevalnikov, ki se razlikujejo po načinu obdelave poslane poizvedbe. Standardni razčlenjevalnik poizvedb dobro deluje za strukturirane poizvedbe, vendar je manj strpen do sintaksnih napak. Hkrati sta razčlenjevalnik poizvedb DisMax in Extended DisMax optimiziran za poizvedbe, podobne naravnemu jeziku. Zasnovani so tako, da obdelujejo preproste besedne zveze, ki jih vnesejo uporabniki, in iščejo posamezne izraze v več poljih z različnimi utežmi.
Poleg tega Solr ponuja tudi tako imenovane poizvedbe o funkcijah, ki omogočajo, da se funkcija kombinira s poizvedbo, da se ustvari določena ocena ustreznosti. Ti razčlenjevalniki se imenujejo Function Query Parser in Function Range Query Parser. Spodnji primer prikazuje slednjega, da izbere vse nabore podatkov za “bmw” (shranjene v podatkovnem polju make) z modeli od 318 do 323:
curl http: // localhost: 8983 / solr / cars / query -d 'q = znamka: bmw &
fq = model: [318 DO 323] '
Naknadna obdelava rezultatov
Pošiljanje poizvedb Apache Solr je en del, drugi rezultat pa je naknadna obdelava rezultata iskanja. Najprej lahko izbirate med različnimi oblikami odzivov - od JSON do XML, CSV in poenostavljeno obliko Ruby. V poizvedbi preprosto določite ustrezen parameter wt. Spodnji primer kode prikazuje to za pridobivanje nabora podatkov v obliki CSV za vse elemente, ki uporabljajo curl z ubežano &:
curl http: // localhost: 8983 / solr / cars / query?q = id: 5 \ & wt = csvRezultat je ločen z vejicami seznam, kot sledi:

Če želite rezultat prejeti kot podatke XML, vendar sta dve izhodni polji make in model samo, zaženite naslednjo poizvedbo:
curl http: // localhost: 8983 / solr / cars / query?q = *: * \ & fl = znamka, model \ & wt = xmlIzhod je drugačen in vsebuje tako glavo odziva kot tudi dejanski odziv:
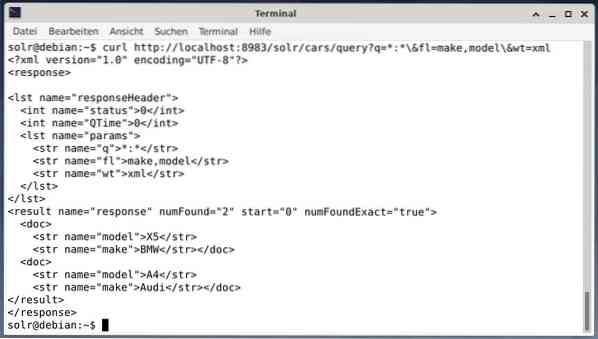
Wget preprosto natisne prejete podatke na stdout. To vam omogoča naknadno obdelavo odziva s standardnimi orodji ukazne vrstice. Če jih naštejemo nekaj, vsebuje jq [9] za JSON, xsltproc, xidel, xmlstarlet [10] za XML in csvkit [11] za format CSV.
Zaključek
Ta članek prikazuje različne načine pošiljanja poizvedb Apache Solr in razlaga, kako obdelati rezultat iskanja. V naslednjem delu boste izvedeli, kako uporabljati Apache Solr za iskanje v PostgreSQL, relacijskem sistemu za upravljanje baz podatkov.
O avtorjih
Jacqui Kabeta je okoljevarstvenica, navdušena raziskovalka, trenerka in mentorica. V več afriških državah je delala v IT industriji in okoljih nevladnih organizacij.
Frank Hofmann je razvijalec informacijskih tehnologij, trener in avtor ter raje dela iz Berlina, Ženeve in Cape Towna. Soavtor knjige za upravljanje paketov Debian, ki je na voljo pri dpmb.org
Povezave in reference
- [1] Apache Solr, https: // lucen.apache.org / solr /
- [2] Frank Hofmann in Jacqui Kabeta: Uvod v Apache Solr. 1. del, http: // linuxhint.com
- [3] Yonik Seelay: Sinrima poizvedb Solr, http: // yonik.com / solr / query-syntax /
- [4] Yonik Seelay: Solr Tutorial, http: // yonik.com / solr-tutorial /
- [5] Apache Solr: Poizvedovanje po podatkih, Tutorialspoint, https: // www.tutorialspoint.com / apache_solr / apache_solr_querying_data.htm
- [6] Lucen, https: // lucen.apache.org /
- [7] SolrJ, https: // lucen.apache.org / solr / guide / 8_8 / using-solrj.html
- [8] curl, https: // curl.se /
- [9] jq, https: // github.com / stedolan / jq
- [10] xmlstarlet, http: // xmlstar.sourceforge.mreža/
- [11] csvkit, https: // csvkit.preberite doktorske dokumente.io / sl / najnovejše /


