Apache Spark je orodje za analitiko podatkov, ki se lahko uporablja za obdelavo podatkov iz HDFS, S3 ali drugih podatkovnih virov v pomnilniku. V tej objavi bomo namestili Apache Spark na Ubuntu 17.10 stroj.
Različica Ubuntu
Za ta vodnik bomo uporabili različico Ubuntu 17.10 (GNU / Linux 4.13.0-38-generični x86_64).
Apache Spark je del ekosistema Hadoop za velike podatke. Poskusite namestiti Apache Hadoop in z njim naredite vzorčno aplikacijo.
Posodabljanje obstoječih paketov
Za začetek namestitve za Spark moramo posodobiti našo napravo z najnovejšimi programskimi paketi, ki so na voljo. To lahko storimo z:
sudo apt-get update && sudo apt-get -y dist-upgradeKer Spark temelji na Javi, ga moramo namestiti na naš računalnik. Nad Java 6 lahko uporabimo katero koli različico Java. Tu bomo uporabljali Javo 8:
sudo apt-get -y namestite openjdk-8-jdk-headlessPrenos datotek Spark
Na našem računalniku so zdaj vsi potrebni paketi. Pripravljeni smo prenesti zahtevane datoteke Spark TAR, da jih lahko začnemo nastavljati in zaženemo tudi vzorčni program s programom Spark.
V tem priročniku bomo namestili Spark v2.3.0 na voljo tukaj:
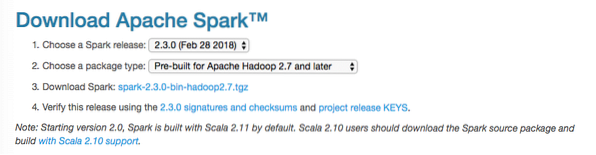
Stran za prenos iskric
S tem ukazom prenesite ustrezne datoteke:
wget http: // www-us.apache.org / dist / spark / spark-2.3.0 / iskra-2.3.0-bin-hadoop2.7.tgzGlede na hitrost omrežja lahko traja nekaj minut, saj je datoteka velike velikosti:
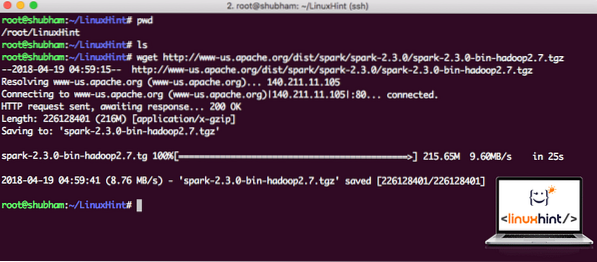
Nalaganje Apache Spark
Zdaj, ko imamo preneseno datoteko TAR, lahko izvlečemo v trenutni imenik:
katran xvzf iskra-2.3.0-bin-hadoop2.7.tgzDokončanje bo trajalo nekaj sekund zaradi velike velikosti datoteke arhiva:
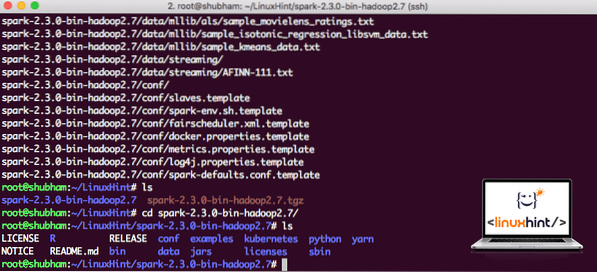
Nearhivirane datoteke v programu Spark
Pri prihodnji nadgradnji Apache Spark lahko povzroči težave zaradi posodobitev poti. Tem težavam se je mogoče izogniti z ustvarjanjem mehke povezave do Sparka. Zaženite ta ukaz, da ustvarite mehko povezavo:
ln -s iskra-2.3.0-bin-hadoop2.7 iskraDodajanje iskrice v pot
Za izvedbo skriptov Spark ga bomo zdaj dodali na pot. Če želite to narediti, odprite datoteko bashrc:
vi ~ /.bashrcTe vrstice dodajte na konec .bashrc, tako da lahko pot vsebuje pot izvršljive datoteke Spark:
SPARK_HOME = / LinuxHint / iskraizvoz POT = $ SPARK_HOME / bin: $ PATH
Zdaj je datoteka videti tako:
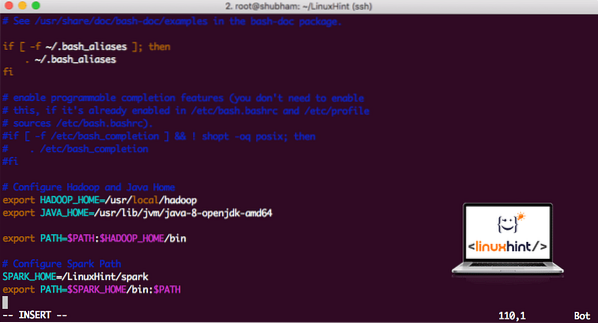
Dodajanje iskrice v POT
Če želite aktivirati te spremembe, zaženite naslednji ukaz za datoteko bashrc:
vir ~ /.bashrcZagon lupine Spark
Zdaj, ko smo tik pred imenikom isker, zaženite naslednji ukaz, da odprete lupino aparka:
./ iskra / koš / iskriloVideli bomo, da se lupina Spark odpre zdaj:
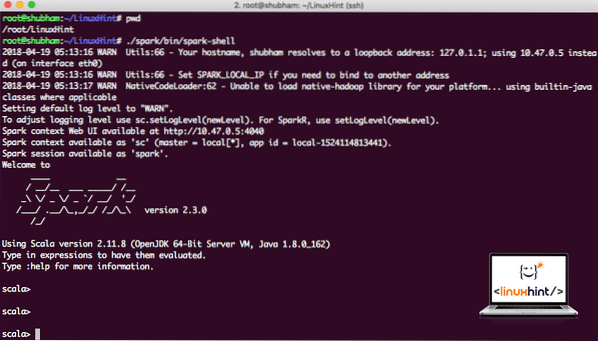
Zagon lupine Spark
V konzoli lahko vidimo, da je Spark odprl tudi spletno konzolo na vratih 404. Oglejmo si ga:
Spletna konzola Apache Spark
Čeprav bomo delovali na sami konzoli, je spletno okolje pomembno mesto, na katerega morate biti pozorni, ko izvajate težka dela Spark, tako da veste, kaj se dogaja v vsakem opravilu Spark, ki ga izvedete.
Preverite različico lupine Spark s preprostim ukazom:
sc.različicoVrnili bomo nekaj takega:
res0: niz = 2.3.0Izdelava vzorca aplikacije Spark s Scalo
Zdaj bomo naredili vzorec aplikacije Word Counter z Apache Spark. Če želite to narediti, najprej naložite besedilno datoteko v kontekst Spark na lupini Spark:
scala> var Podatki = sc.textFile ("/ root / LinuxHint / spark / README.md ")Podatki: org.apache.iskra.rdd.RDD [String] = / root / LinuxHint / spark / README.md MapPartitionsRDD [1] pri textFile na: 24
scala>
Zdaj je treba besedilo v datoteki razdeliti na žetone, s katerimi lahko upravlja Spark:
scala> var žetoni = podatki.flatMap (s => s.razdeli (""))žetoni: org.apache.iskra.rdd.RDD [String] = MapPartitionsRDD [2] pri flatMap na: 25
scala>
Zdaj inicializirajte število za vsako besedo na 1:
scala> var žetoni_1 = žetoni.zemljevid (s => (s, 1))žetoni_1: org.apache.iskra.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] na zemljevidu na: 25
scala>
Na koncu izračunajte pogostost vsake besede v datoteki:
var sum_each = žetoni_1.reduceByKey ((a, b) => a + b)Čas je, da si ogledamo rezultate programa. Zberite žetone in njihovo število:
scala> sum_each.zbrati ()res1: Array [(String, Int)] = Array ((paket, 1), (Za, 3), (Programi, 1), (obdelava.,1), (Ker, 1), (The, 1), (stran) (http: // spark.apache.org / dokumentacija.html).,1), (grozd.,1), (its, 1), [[run, 1], (than, 1), (APIs, 1), (have, 1), (Try, 1), (computation, 1), (through, 1 ), (več, 1), (To, 2), (graf, 1), (Panj, 2), (shranjevanje, 1), (["Navedba, 1), (Do, 2), (" preja " , 1), (Enkrat, 1), (["Uporabno, 1), (raje, 1), (SparkPi, 2), (motor, 1), (različica, 1), (datoteka, 1), (dokumentacija ,, 1), (obdelava ,, 1), (the, 24), (are, 1), (sistemi.,1), (params, 1), (ne, 1), (drugačno, 1), (glej, 2), (interaktivno, 2), (R ,, 1), (podano.,1), (if, 4), (build, 4), (when, 1), (be, 2), (Tests, 1), (Apache, 1), (thread, 1), (programi ,, 1 ), (vključno s 4), (./ bin / run-example, 2), (Spark.,1), (paket.,1), (1000).count (), 1), (Različice, 1), (HDFS, 1), (D…
scala>
Odlično! Zagnali smo lahko preprost primer števca besed z uporabo programskega jezika Scala z besedilno datoteko, ki je že prisotna v sistemu.
Zaključek
V tej lekciji smo preučili, kako lahko namestimo in začnemo uporabljati Apache Spark v Ubuntu 17.10 in na njem zaženite tudi vzorčno aplikacijo.
Tukaj preberite več objav na osnovi Ubuntuja.


