Apache Hadoop je velika podatkovna rešitev za shranjevanje in analizo velikih količin podatkov. V tem članku bomo podrobno opisali zapletene korake za namestitev Apache Hadoop, da boste čim hitreje začeli z njim v Ubuntuju. V tej objavi bomo namestili Apache Hadoop na Ubuntu 17.10 stroj.
Različica Ubuntu
Za ta vodnik bomo uporabili različico Ubuntu 17.10 (GNU / Linux 4.13.0-38-generični x86_64).
Posodabljanje obstoječih paketov
Za začetek namestitve Hadoopa moramo posodobiti našo napravo z najnovejšimi programskimi paketi, ki so na voljo. To lahko storimo z:
sudo apt-get update && sudo apt-get -y dist-upgradeKer Hadoop temelji na Javi, ga moramo namestiti na naš računalnik. Nad Java 6 lahko uporabimo katero koli različico Java. Tu bomo uporabljali Javo 8:
sudo apt-get -y namestite openjdk-8-jdk-headlessPrenos datotek Hadoop
Na našem računalniku so zdaj vsi potrebni paketi. Pripravljeni smo prenesti zahtevane datoteke Hadoop TAR, da jih lahko začnemo nastavljati in zaženemo tudi vzorčni program s Hadoop.
V tem priročniku bomo namestili Hadoop v3.0.1. S tem ukazom prenesite ustrezne datoteke:
wget http: // ogledalo.cc.kolumbija.edu / pub / software / apache / hadoop / common / hadoop-3.0.1 / hadoop-3.0.1.katran.gzGlede na hitrost omrežja lahko traja nekaj minut, saj je datoteka velike velikosti:
Nalaganje Hadoop
Najdite najnovejše binarne datoteke Hadoop tukaj. Zdaj, ko imamo preneseno datoteko TAR, lahko izvlečemo v trenutni imenik:
katran xvzf hadoop-3.0.1.katran.gzDokončanje bo trajalo nekaj sekund zaradi velike velikosti datoteke arhiva:
Hadoop arhiviran
Dodana je nova uporabniška skupina Hadoop
Ker Hadoop deluje prek HDFS, lahko nov datotečni sistem razbremeni naš lastni datotečni sistem tudi na Ubuntuju. Da bi se izognili tej koliziji, bomo ustvarili popolnoma ločeno skupino uporabnikov in jo dodelili Hadoopu, tako da bo imel lastna dovoljenja. S tem ukazom lahko dodamo novo uporabniško skupino:
addgroup hadoopVideli bomo nekaj takega:
Dodajanje uporabniške skupine Hadoop
V to skupino smo pripravljeni dodati novega uporabnika:
useradd -G hadoop hadoopuserUpoštevajte, da so vsi ukazi, ki jih izvajamo, korenski uporabnik. Z ukazom aove smo v skupino, ki smo jo ustvarili, lahko dodali novega uporabnika.
Da uporabniku Hadoop omogočamo izvajanje operacij, mu moramo zagotoviti tudi korenski dostop. Odprite / etc / sudoers datoteka s tem ukazom:
sudo visudoPreden karkoli dodamo, bo datoteka videti tako:
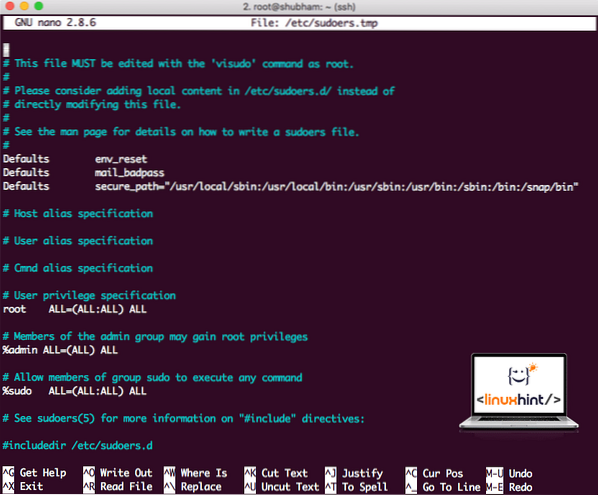
Datoteka Sudoers, preden kar koli dodate
Na konec datoteke dodajte naslednjo vrstico:
hadoopuser VSE = (VSE) VSEZdaj bo datoteka videti tako:
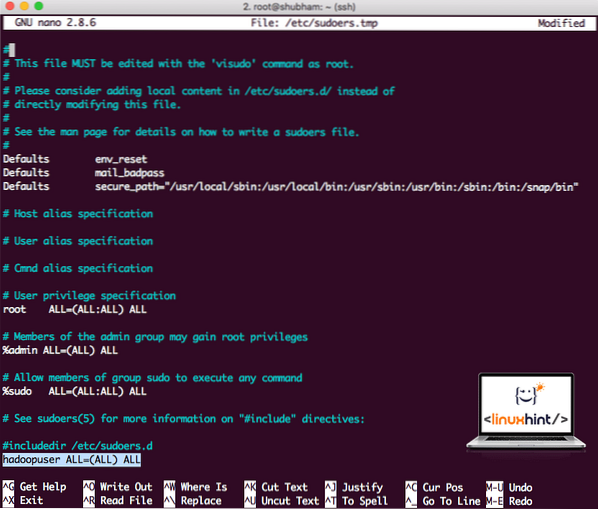
Datoteka Sudoers po dodajanju uporabnika Hadoop
To je bila glavna nastavitev za zagotavljanje platforme Hadoop za izvajanje akcij. Zdaj smo pripravljeni nastaviti eno vozlišče Hadoop.
Nastavitev Hadoop Single Node: samostojni način
Ko gre za resnično moč Hadoopa, je običajno nastavljen na več strežnikih, tako da lahko meri nad veliko količino nabora podatkov, ki je v Distribuirani datotečni sistem Hadoop (HDFS). To je običajno v redu z okolji za odpravljanje napak in se ne uporablja za produkcijsko uporabo. Da bo postopek enostaven, bomo razložili, kako lahko tukaj naredimo eno vozlišče za Hadoop.
Ko končamo z namestitvijo Hadoop, bomo na Hadoopu zagnali tudi vzorčno aplikacijo. Od zdaj je datoteka Hadoop poimenovana kot hadoop-3.0.1. preimenujmo ga v hadoop za enostavnejšo uporabo:
mv hadoop-3.0.1 hadoopDatoteka je zdaj videti tako:
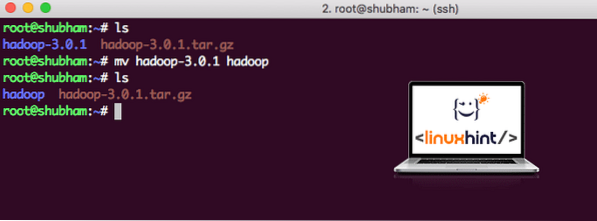
Premikanje Hadoop
Čas je, da uporabimo uporabnika hadoop, ki smo ga ustvarili prej, in uporabniku dodelimo lastništvo te datoteke:
chown -R hadoopuser: hadoop / koren / hadoopBoljša lokacija za Hadoop bo imenik / usr / local /, zato ga premaknimo tja:
mv hadoop / usr / local /cd / usr / local /
Dodajanje Hadoopa v pot
Za izvajanje skriptov Hadoop ga bomo zdaj dodali na pot. Če želite to narediti, odprite datoteko bashrc:
vi ~ /.bashrcTe vrstice dodajte na konec .bashrc, tako da lahko pot vsebuje pot do izvršljive datoteke Hadoop:
# Konfigurirajte Hadoop in Java Homeizvoz HADOOP_HOME = / usr / local / hadoop
izvoz JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64
izvoz POT = $ PATH: $ HADOOP_HOME / bin
Datoteka je videti tako:
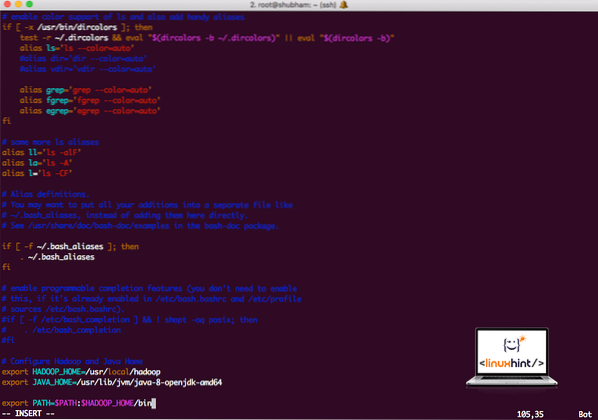
Dodajanje Hadoopa v pot
Ker Hadoop uporablja Javo, moramo to sporočiti datoteki okolja Hadoop hadoop-env.sh kjer se nahaja. Lokacija te datoteke se lahko razlikuje glede na različice Hadoop. Če želite enostavno najti, kje se nahaja ta datoteka, zaženite naslednji ukaz tik pred imenikom Hadoop:
najdi hadoop / -ime hadoop-env.shDobili bomo izhod za lokacijo datoteke:
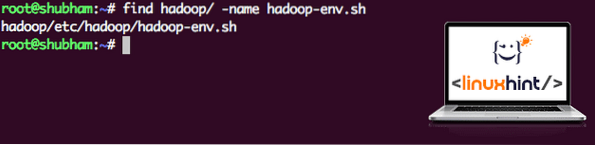
Lokacija datoteke okolja
Uredimo to datoteko, da obvestimo Hadoop o lokaciji Java JDK in jo vstavimo v zadnjo vrstico datoteke ter jo shranimo:
izvoz JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64Namestitev in namestitev Hadoop je zdaj končana. Zdaj smo pripravljeni zagnati našo vzorčno aplikacijo. Toda počakajte, nikoli nismo naredili vzorčne prijave!
Izvajanje vzorčne aplikacije s Hadoop
Pravzaprav namestitev Hadoop-a vsebuje vgrajeno vzorčno aplikacijo, ki je pripravljena za zagon, ko končamo z namestitvijo Hadoop-a. Sliši se dobro, kajne?
Zaženite naslednji ukaz, da zaženete primer JAR:
hadoop jar / root / hadoop / share / hadoop / mapreduce / hadoop-mapreduce-examples-3.0.1.jar wordcount / root / hadoop / README.txt / root / outputHadoop bo pokazal, koliko obdelave je opravil na vozlišču:
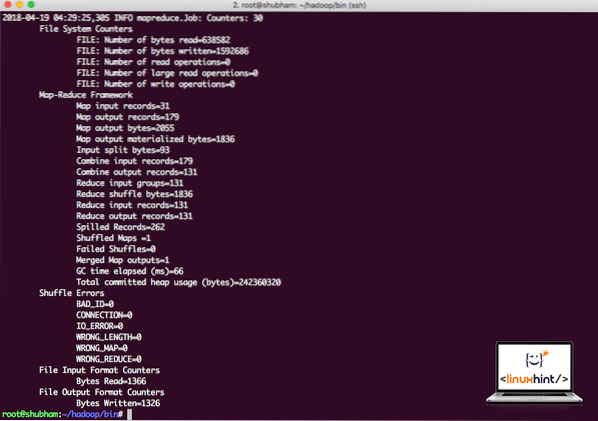
Statistika obdelave Hadoop
Ko izvedete naslednji ukaz, vidimo datoteko part-r-00000 kot izhod. Pojdite naprej in si oglejte vsebino rezultata:
mačji del-r-00000Dobili boste nekaj takega:
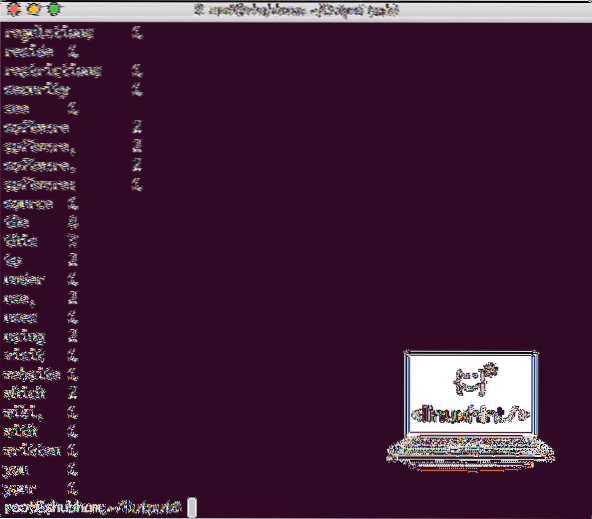
Število besed, ki jih izpiše Hadoop
Zaključek
V tej lekciji smo preučili, kako lahko namestimo in začnemo uporabljati Apache Hadoop v Ubuntu 17.10 stroj. Hadoop je odličen za shranjevanje in analizo velike količine podatkov in upam, da vam bo ta članek pomagal hitro začeti uporabljati na Ubuntuju.


