Predpogoj
Za branje podatkov iz Kafke morate namestiti potrebno knjižnico python. Python3 se v tej vadnici uporablja za pisanje skripta potrošnika in proizvajalca. Če paket pip ni nameščen prej v vašem operacijskem sistemu Linux, morate namestiti pip, preden namestite knjižnico Kafka za python. python3-kafka se v tej vadnici uporablja za branje podatkov iz Kafke. Za namestitev knjižnice zaženite naslednji ukaz.
$ pip namestite python3-kafkaBranje preprostih besedilnih podatkov iz Kafke
Proizvajalec lahko pošlje različne vrste podatkov o določeni temi, ki jo lahko prebere potrošnik. V tem delu te vadnice je prikazano, kako lahko od Kafke pošljemo in prejmemo preproste besedilne podatke s pomočjo proizvajalca in potrošnika.
Ustvarite datoteko z imenom proizvajalec1.py z naslednjim skriptom python. KafkaProducer modul je uvožen iz knjižnice Kafka. Seznam posrednikov mora določiti v času inicializacije objekta proizvajalca, da se poveže s strežnikom Kafka. Privzeta vrata Kafke so '9092". Argument bootstrap_servers se uporablja za določitev imena gostitelja z vrati. "First_Topic'je nastavljeno kot ime teme, s katero bo proizvajalcu poslano besedilno sporočilo. Nato preprosto besedilno sporočilo, 'Pozdravljeni iz Kafke'je poslano z uporabo pošlji () metoda KafkaProducer na temo, 'First_Topic".
proizvajalec1.py:
# Uvozi KafkaProducer iz knjižnice Kafkaiz kafka import KafkaProducer
# Določite strežnik z vrati
bootstrap_servers = ['localhost: 9092']
# Določite ime teme, kjer bo sporočilo objavljeno
topicName = 'First_Topic'
# Inicializirajte spremenljivko proizvajalca
proizvajalec = KafkaProducer (bootstrap_servers = bootstrap_servers)
# Objavi besedilo v določeni temi
proizvajalec.pošlji (topicName, b'Halo od kafka ... ')
# Natisni sporočilo
print ("Sporočilo poslano")
Ustvarite datoteko z imenom potrošnik1.py z naslednjim skriptom python. KafkaConsumer modul je uvožen iz knjižnice Kafka za branje podatkov iz Kafke. sys tukaj se uporablja modul za zaključek skripta. Za branje podatkov iz Kafke se v skriptu potrošnika uporabljata isto ime gostitelja in številka vrat proizvajalca. Ime teme potrošnika in proizvajalca mora biti enako, kar je „Prva_tema". Nato se potrošniški objekt inicializira s tremi argumenti. Ime teme, ID skupine in podatki o strežniku. za zanka se tukaj uporablja za branje besedila, poslanega od proizvajalca Kafka.
potrošnik1.py:
# Uvozi KafkaConsumer iz knjižnice Kafkaiz kafka import KafkaConsumer
# Uvozi modul sys
uvoz sys
# Določite strežnik z vrati
bootstrap_servers = ['localhost: 9092']
# Določite ime teme, od kod bo prejeto sporočilo
topicName = 'First_Topic'
# Inicializirajte potrošniško spremenljivko
potrošnik = KafkaConsumer (imeName, group_id = 'group1', bootstrap_servers =
bootstrap_servers)
# Preberite in natisnite sporočilo potrošnika
za sporočilo pri porabniku:
print ("Ime teme =% s, Sporočilo =% s"% (sporoč.tema, sporoč.vrednost))
# Prekinite skript
sys.izhod ()
Izhod:
Zaženite naslednji ukaz iz enega terminala, da zaženete skript proizvajalca.
$ python3 proizvajalec1.pyPo pošiljanju sporočila se prikaže naslednji izhod.

Zaženite naslednji ukaz iz drugega terminala, da zaženete potrošniški skript.
$ python3 potrošnik1.pyRezultat prikazuje ime teme in besedilno sporočilo, poslano od proizvajalca.

Branje podatkov v formatu JSON iz Kafke
Podatke v obliki JSON lahko pošlje proizvajalec Kafka in jih prebere potrošnik Kafka json modul pythona. Kako je mogoče podatke JSON serializirati in odstraniti iz serije, preden jih pošljete in sprejmete z uporabo modula python-kafka, je prikazano v tem delu te vadnice.
Ustvarite python skript z imenom proizvajalec2.py z naslednjim skriptom. Drugi modul z imenom JSON se uvozi z KafkaProducer modul tukaj. vrednost_serializator argument se uporablja z bootstrap_servers argument tukaj za inicializacijo predmeta proizvajalca Kafka. Ta argument pomeni, da bodo podatki JSON kodirani z uporabo 'utf-8'nabor znakov v času pošiljanja. Nato se podatki v obliki JSON pošljejo v imenovano temo JSONtopic.
proizvajalec2.py:
# Uvozi KafkaProducer iz knjižnice Kafkaiz kafka import KafkaProducer
# Uvozite modul JSON za serializacijo podatkov
uvoz json
# Inicializirajte proizvajalčevo spremenljivko in nastavite parameter za kodiranje JSON
proizvajalec = KafkaProducer (bootstrap_servers =
['localhost: 9092'], value_serializer = lambda v: json.odlagališča (v).encode ('utf-8'))
# Pošljite podatke v obliki JSON
proizvajalec.send ('JSONtopic', 'name': 'fahmida', 'email': '[email protected]')
# Natisni sporočilo
print ("Sporočilo poslano v JSONtopic")
Ustvarite python skript z imenom potrošnik2.py z naslednjim skriptom. KafkaConsumer, sys in JSON moduli so uvoženi v tem skriptu. KafkaConsumer modul se uporablja za branje podatkov v formatu JSON iz Kafke. Modul JSON se uporablja za dekodiranje kodiranih podatkov JSON, poslanih od proizvajalca Kafke. Sys modul se uporablja za zaključek skripta. vrednost_deserializator argument se uporablja z bootstrap_servers da določite, kako se bodo dešifrirali podatki JSON. Naslednji, za zanka se uporablja za tiskanje vseh potrošniških zapisov in podatkov JSON, pridobljenih iz Kafke.
potrošnik2.py:
# Uvozi KafkaConsumer iz knjižnice Kafkaiz kafka import KafkaConsumer
# Uvozi modul sys
uvoz sys
# Uvozite modul json za serializacijo podatkov
uvoz json
# Inicializirajte potrošniško spremenljivko in nastavite lastnost za dekodiranje JSON
potrošnik = KafkaConsumer ('JSONtopic', bootstrap_servers = ['localhost: 9092'],
vrednost_deserializator = lambda m: json.obremenitve (m.decode ('utf-8')))
# Preberite podatke iz kafke
za sporočilo v potrošniku:
print ("Potrošniški zapisi: \ n")
natisni (sporočilo)
print ("\ nBranje iz podatkov JSON \ n")
print ("Ime:", sporočilo [6] ['ime'])
print ("E-pošta:", sporočilo [6] ['email'])
# Prekinite skript
sys.izhod ()
Izhod:
Zaženite naslednji ukaz iz enega terminala, da zaženete skript proizvajalca.
$ python3 proizvajalec2.pySkript bo po pošiljanju podatkov JSON natisnil naslednje sporočilo.

Zaženite naslednji ukaz iz drugega terminala, da zaženete potrošniški skript.
$ python3 potrošnik2.pyPo zagonu skripta se prikaže naslednji izhod.
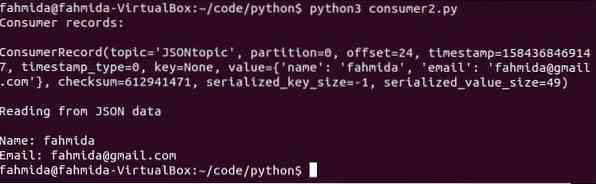
Zaključek:
Podatke lahko s pomočjo pythona pošilja in prejema Kafka v različnih oblikah. Podatke lahko shranite v bazo podatkov in jih pridobite iz baze podatkov s pomočjo Kafke in pythona. Doma sem, ta vadnica bo uporabniku pythona pomagala, da začne sodelovati s Kafko.


