Ta članek vam prikazuje, kako najti dvojnike v podatkih in odstraniti dvojnike s pomočjo funkcij Pandas Python.
V tem članku smo uporabili nabor podatkov o prebivalstvu različnih držav v ZDA, ki je na voljo v .csv. Prebrali bomo .csv za prikaz izvirne vsebine te datoteke, kot sledi:
uvozi pande kot pddf_state = pd.read_csv ("C: / Uporabniki / DELL / Namizje / prebivalstvo_ds.csv ")
natisni (df_state)
Na naslednjem posnetku zaslona si lahko ogledate podvojene vsebine te datoteke:
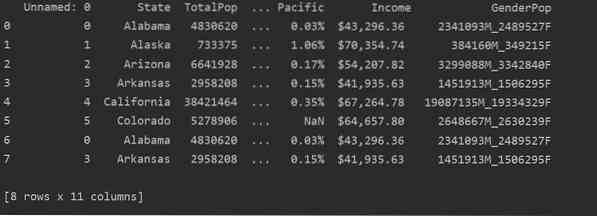
Prepoznavanje dvojnikov v Pandas Python
Ugotoviti je treba, ali imajo podatki, ki jih uporabljate, podvojene vrstice. Če želite preveriti podvajanje podatkov, lahko uporabite katero koli metodo iz naslednjih oddelkov.
1. metoda:
Preberite datoteko csv in jo posredujte v podatkovni okvir. Nato poiščite podvojene vrstice s pomočjo podvojeno () funkcijo. Na koncu uporabite izjavo print za prikaz podvojenih vrstic.
uvozi pande kot pddf_state = pd.read_csv ("C: / Uporabniki / DELL / Namizje / prebivalstvo_ds.csv ")
Dup_Rows = df_state [df_state.podvojeno ()]
print ("\ n \ n Podvojene vrstice: \ n ".format (Dup_Rows))
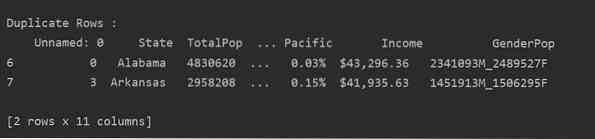
2. metoda:
S to metodo se je_dvostručen stolpec bo dodan na konec tabele in označen kot "True" v primeru podvojenih vrstic.
uvozi pande kot pddf_state = pd.read_csv ("C: / Uporabniki / DELL / Namizje / prebivalstvo_ds.csv ")
df_state ["is_duplicate"] = df_state.podvojeno ()
natisni ("\ n ".format (df_state))
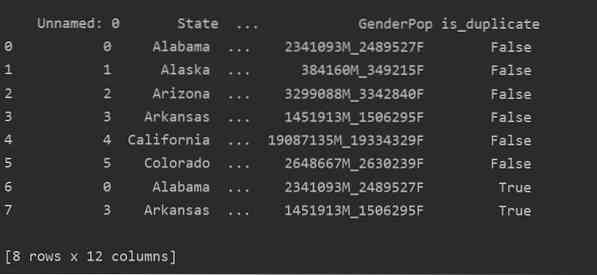
Odstranjevanje dvojnikov v Pandas Python
Podvojene vrstice lahko odstranite iz podatkovnega okvira z naslednjo sintakso:
drop_duplicates (subset = ", keep =", inplace = False)
Zgornji trije parametri so neobvezni in so podrobneje razloženi spodaj:
obdrži: ta parameter ima tri različne vrednosti: First, Last in False. Prva vrednost obdrži prvi pojav in odstrani nadaljnje dvojnike, zadnja vrednost zadrži le zadnji pojav in odstrani vse prejšnje dvojnike, vrednost False pa vse podvojene vrstice.
podnabor: oznaka, ki se uporablja za identifikacijo podvojenih vrstic
na mestu: vsebuje dva pogoja: True in False. Ta parameter bo odstranil podvojene vrstice, če je nastavljeno na True.
Odstranite dvojnike, obdržite samo prvo pojavitev
Ko uporabite »obdrži = prvi«, se bo obdržal samo pojav prve vrstice, vsi drugi dvojniki pa bodo odstranjeni.
Primer
V tem primeru se bo obdržala samo prva vrstica, preostali dvojniki pa bodo izbrisani:
uvozi pande kot pddf_state = pd.read_csv ("C: / Uporabniki / DELL / Namizje / prebivalstvo_ds.csv ")
Dup_Rows = df_state [df_state.podvojeno ()]
print ("\ n \ n Podvojene vrstice: \ n ".format (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (obdrži = 'first')
print ('\ n \ nResult DataFrame po odstranitvi dvojnika: \ n', DF_RM_DUP.glava (n = 5))
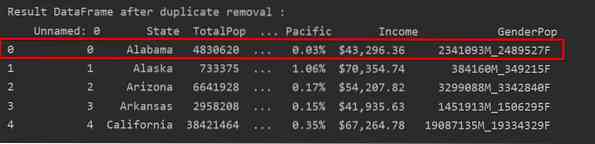
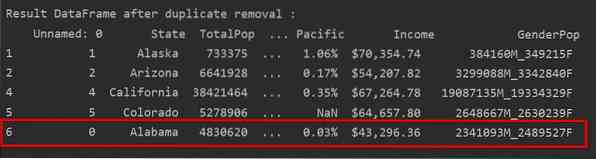
Na naslednjem posnetku zaslona je zadržani pojav prve vrstice označen z rdečo, preostala podvajanja pa so odstranjena:
Odstranite dvojnike, pri čemer ohranite samo zadnjo pojavitev
Ko uporabite »obdrži = zadnji«, bodo odstranjene vse podvojene vrstice, razen zadnjega.
Primer
V naslednjem primeru so odstranjene vse podvojene vrstice, razen le zadnjega.
uvozi pande kot pddf_state = pd.read_csv ("C: / Uporabniki / DELL / Namizje / prebivalstvo_ds.csv ")
Dup_Rows = df_state [df_state.podvojeno ()]
print ("\ n \ n Podvojene vrstice: \ n ".format (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (obdrži = 'zadnji')
print ('\ n \ nResult DataFrame po odstranitvi dvojnika: \ n', DF_RM_DUP.glava (n = 5))
Na naslednji sliki se dvojniki odstranijo in ohrani se le zadnja vrstica:
Odstrani vse podvojene vrstice
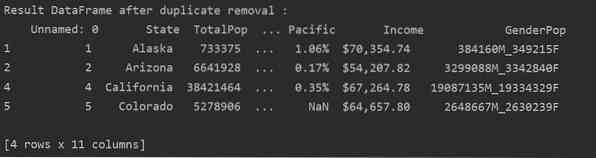
Če želite iz tabele odstraniti vse podvojene vrstice, nastavite »keep = False«, kot sledi:
uvozi pande kot pddf_state = pd.read_csv ("C: / Uporabniki / DELL / Namizje / prebivalstvo_ds.csv ")
Dup_Rows = df_state [df_state.podvojeno ()]
print ("\ n \ n Podvojene vrstice: \ n ".format (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (obdrži = False)
print ('\ n \ nResult DataFrame po odstranitvi dvojnika: \ n', DF_RM_DUP.glava (n = 5))
Kot lahko vidite na naslednji sliki, so vsi dvojniki odstranjeni iz podatkovnega okvira:
Odstranite sorodne dvojnike iz določenega stolpca
Funkcija privzeto preveri podvojene vrstice iz vseh stolpcev v danem podatkovnem okviru. Ime stolpca pa lahko določite tudi s parametrom podnabora.
Primer
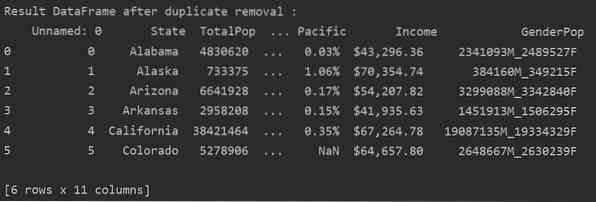
V naslednjem primeru so vsi povezani dvojniki odstranjeni iz stolpca "Države".
uvozi pande kot pddf_state = pd.read_csv ("C: / Uporabniki / DELL / Namizje / prebivalstvo_ds.csv ")
Dup_Rows = df_state [df_state.podvojeno ()]
print ("\ n \ n Podvojene vrstice: \ n ".format (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (subset = 'State')
print ('\ n \ nResult DataFrame po odstranitvi dvojnika: \ n', DF_RM_DUP.glava (n = 6))
Zaključek
Ta članek vam je pokazal, kako odstranite podvojene vrstice iz podatkovnega okvira s pomočjo drop_duplicates () funkcija v Pandas Python. S to funkcijo lahko podatke počistite tudi zaradi podvajanja ali odvečnosti. Članek vam je tudi pokazal, kako prepoznati vse dvojnike v svojem podatkovnem okviru.


