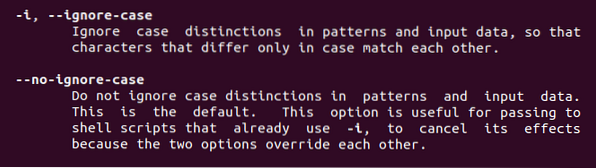
Iz tega ukaza bomo našli dve zgoraj opisani funkciji. -Ignorirati želim velike primere. Kadar koli se uporablja ta ključna beseda, se odstrani naklonjenost.
Predpogoj
Za izpolnitev funkcionalnosti te funkcije v operacijskem sistemu Linux moramo imeti nameščen operacijski sistem Linux. Po konfiguraciji boste navedli zahtevane uporabniške podatke, s pomočjo katerih bo uporabnik prijavljen. Poleg tega bo uporabnik lahko po vnosu uporabniškega imena in gesla dostopal do vseh vgrajenih funkcij operacijskega sistema. Ko končate dostop do namizja, morate dostopati do terminala, saj je treba na njem izvajati ukaze.
Primer 1:
V tem primeru bomo videli, kako grep pomaga pri izogibanju občutljivosti na velike in male črke. Razmislite o datoteki z imenom files11.txt. Datoteka vsebuje naslednje podatke; kot lahko vidite, je beseda mango napisana na različne načine, nekatere besede so z velikimi, nekatere pa z malimi črkami. Z uporabo ukaza cat bomo prikazali podatke datoteke.
$ cat datoteke11.txt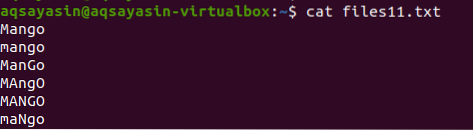
Ko je ukaz uporabljen za prikaz podatkov, je mogoče opaziti, da je prikazana edina beseda, ki se ujema s črko, ki je prisotna v ukazu. Vse črke so napisane z malimi črkami.
Datoteke mango $ grep11.txt
Zdaj, da bi razumeli koncept neobčutljivosti na velike črke, bomo v ukazu uporabili “-I” za obravnavo občutljivosti na male črke tako, da zagotovimo vse podatke v datoteki, ki se ujemajo z nizom v ukazu.
$ grep -I mango datoteke11.txt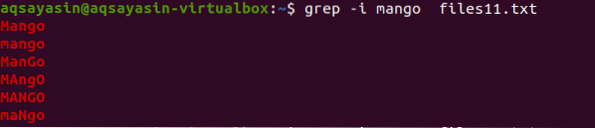
Iz izhoda boste izvedeli, da so vsi podatki, ki se ujemajo z besedo "mango", prikazani bodisi z nekaterimi besedami, zapisanimi z velikimi črkami, nekateri pa z malimi.
2. primer
Ta primer je podoben prvemu, razlika je v tem, da dobimo samo eno besedo. Ta ukaz pomaga pri pridobivanju celotnega niza, tako da ga ujema z besedo, navedeno v ukazu. Dovolite nam datoteko filea.txt. kot primer želimo pridobiti zapis glede na dano ujemanje.
$ cat filea.txt
Zdaj uporabite isti ukaz, da prezrete primer in prikažete izhod. Tehnična beseda se prikaže tako, da se med velikimi in malimi črkami izbere velika črka.

3. primer
Druga metoda uporabe grepa za prezrtje velikih črk je, da najprej uvedemo ime datoteke in kasneje uporabimo ukaz -I z grepom po "|" operater. Cat se uporablja skupaj z “|”. Dovolite nam datoteko z imenom file24.txt. kot primer.
$ Cat datoteka24.txt | grep -I “Aqsa”Ta ukaz prikliče besedo »Aqsa« v velikih in malih črkah.

4. primer
Premik k drugemu primeru. Tu bomo prikazali podatke datoteke, ki vsebuje besedo "moj". Tukaj iskanje poteka z uvedbo imenika, tako da bo ukaz razvrstil besedo v vseh datotekah s pripono .txt v sistemu.
$ grep -Jaz / home / aqsayasin / *.txt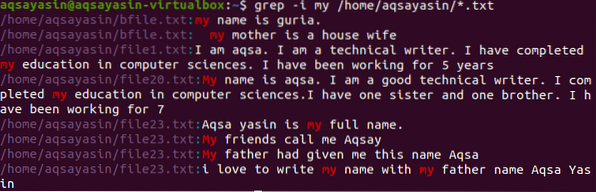
Zgornja slika prikazuje izhod, pridobljen iz ukaza. Označena je beseda "moja", to je v obeh primerih. Nekatere datoteke ga vsebujejo z malimi črkami, druge pa z velikimi. Prikažejo se tudi naslov datotek in imena datotek.
Primer 5
Ta primer je mogoče uporabiti za imenik, v katerem so vse datoteke. Omejitve bodo uporabljene za prikaz konkretnega rezultata, ki se ujema z besedo, ki smo jo določili v ukazu. Beseda »is« se uporablja za iskanje v vseh datotekah, ki so v sistemu.
$ grep -jaz / home / aqsayasin / file *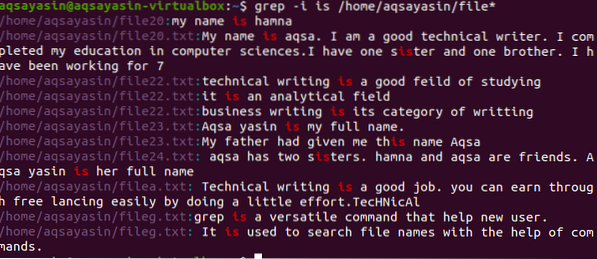
Na izhodu so prikazani celotni nizi, ki vsebujejo ujemajočo se besedo. Kot je "je", je zapisano ločeno ali združeno z drugo besedo i.e. sestra.
Primer 6
Naslednji ukaz prikazuje, kako -iw deluje skupaj v ukazu. Poleg tega iskanje poteka po dveh besedah v eni datoteki. Poševnica in »|« se uporabljajo za opis dveh besed v datoteki, medtem ko se -w uporablja za natančno ujemanje ustrezne besede v datoteki.
$ grep -iw 'hamna \ | house' datoteka21.txt$ grep 'hamn \ | house' datoteka21.txt

-Ne upoštevam velikih in malih črk. V zgornjem primeru lahko vidimo, da prisotnost -w z -I omogoča, da hiša v prvem ukazu ni upoštevana, ker -w omogoča natančno ujemanje. V drugem ukazu smo odstranili oba -iw, zato sta obe besedi prikazani po ujemanju v nizu.
7. primer
Več besed se išče z uporabo druge metode. Obe besedi iščeta v isti datoteki, ti besedi sta "delo" in "zaslužek". Zaslužek je pridobljen z besedo učenje, upoštevajte tudi, da je vsaka beseda ločena od ključne besede -e.
$ grep -I -e job -e zaslužim filea.txt
Zgornja slika prikazuje celotne nize v odstavku glede besed, ki so prisotne v ukazu. Tako kot zgornji primeri sem tudi jaz prezrl vsakršno razlikovanje med besedami delo in zaslužiti.
Primer 8
V tem primeru je iskanje dveh besed prisotnih v vseh datotekah .razširitev txt. Ti dve besedi sta ločeni z -e, saj je -e pravi način za ločevanje dveh besed. V dobljenih izhodih bodo obe besedi prikazani v vseh datotekah z razširitvijo besedila. Pridobljen je in prikazan je celoten naslov datoteke. -Ignoriral bom razliko med velikimi in malimi črkami in prikazal obe besedi, ki sta prisotni v vseh datotekah.
$ grep -I -e job -e zasluži / home / aqsayasin / *.txt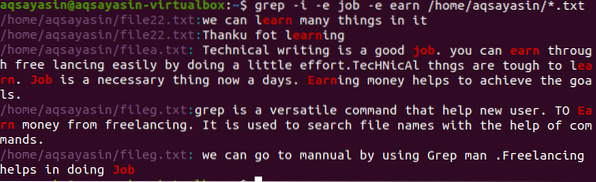
Zaključek
V tem priročniku smo uporabili najpreprostejši primer za podrobnejši opis koncepta občutljivosti na velike in male črke. Po najboljših močeh smo se potrudili, da smo preučili vsak vidik, da bi izboljšali znanje o grepu.


