Funkcija grep je iskanje besedila in uporaba pogojev zanje. Uporablja se za iskanje v več datotekah. Grep lahko prepozna besedilne vrstice v njem in se odloči, da bo nadalje uporabil različna dejanja, ki vključujejo rekurzivno funkcijo ali obratno iskanje in prikaže številko vrstice kot izhod itd. Posebni znaki so regularni izrazi, ki se uporabljajo v ukazih za izvajanje več dejanj, kot so #,%, *, &, $, @ itd. V tem članku bomo uporabili posebne znake. Grep dovoljuje argumente kot nize, ki so podani kot regularni izraz. Ima tudi možnost, da v njej nadomesti besedo ali besedno zvezo. Posebni znaki se ne uporabljajo samo kot ime datoteke, temveč tudi kot podatki, ki so znotraj datoteke.
Predpogoj
Za njegovo izvajanje moramo imeti operacijski sistem Linux. Za zagon Linuxa moramo imeti vnaprej nameščeno navidezno polje. Po uspešni namestitvi Linuxa ga boste konfigurirali z nekaj koristnimi informacijami. Naslednji korak je vstop na domačo stran Ubuntuja Linux. Če navedete uporabniško ime in geslo, boste lahko dostopali do vseh aplikacij -typectrl + alt + t, da odprete terminal.
Uporaba "$"
Če želite razumeti koncept posebnega znaka “$” v ukazu grep, morate imeti datoteko z imenom file21.txt. "$" Se uporablja za prikaz vseh vrstic, ki imajo znak, definiran za "$", ki je podpičje, tj.e., '; $'. Z ukazom cat lahko prikažemo vso ustrezno vsebino.
$ Cat datoteka21.txt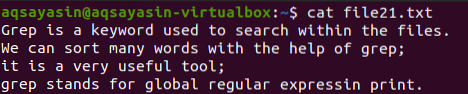
Zdaj bomo v naslednjem ukazu uporabili znak, da bomo razumeli, kako deluje. “-E” pomaga prikazati natančno ujemanje v datoteki.
$ grep -e '; $' datoteka21.txt
Zgornji izhod prikazuje vse vrstice v datoteki s podpičjem “;” na koncu. Ustrezni rezultat je poudarjen v vsaki vrstici.
Uporaba "
To je preprost primer regularnega izraza. V katerem koli stavku grep se enojni narekovaji uporabljajo, kadar želimo ujemati katero koli besedo v datoteki. Podobno smo omenjali ta primer, da je bil uporabniku natančen in razumljiv.
$ grep -e datoteka 'Aqsa '23.txtIzhod bo vseboval vse stavke, ki vsebujejo besedo Aqsa, saj smo to besedo iskali v ukazu.

Uporaba []
V oglatih oklepajih se omenja beseda, ki jo je treba iskati med dvema paroma oglatih oklepajev. Tem kvadratnim oklepajem v ukazu sledi »*«. Poleg tega smo v ukazu uporabili -n -I -w -e, da natančno dobimo izhod s številko vrstice, pri čemer ne upoštevamo občutljivosti na velike in male črke, in dobimo natančno ujemanje, ki se je v datoteki zgodilo več kot enkrat. Uporabili bomo datoteko fileg.txt za prikaz podatkov, ki so v njem. -E se uporablja kot razširjeni regularni izraz, kadar koli v ukazu uporabimo kateri koli znak.
$ Cat datotekag.txt
Zdaj bomo uporabili naslednjo poizvedbo.
$ grep -noiwe -e '[] * datoteka [] *'.txt
Kje fileg.txt je zadevna datoteka. Na izhodu je prikazana beseda "the", kjer koli je v datoteki, skupaj s številko vrstice. Prikazana je samo beseda, ne pa tudi celotni stavek, ker smo uporabili -w in -e za prikaz njegove pojavnosti in natančnost.
Uporaba '-'
'-' se uporablja v ukazu za iskanje ujemanja v datoteki. -niw spet predstavlja enak pomen, kot je opisan v zgoraj omenjenem primeru. -m prikazuje prvo vrstico, ki vsebuje besedo v obstoječi datoteki.
$ grep -niw -m 3 'tehnična' datoteka1.txt
Rezultat prikazuje vrstice, ki vsebujejo besedo tehnični. Prikaže se tudi številka vrstice z besedo "tehnični", ki je v 1 in 4.
Uporaba "|"
Ta posebni znak se uporablja na več načinov. Na splošno se uporablja kot operater OR, da lahko izbere dve imeni. V ukazu grep se uporablja za delovanje, tako da pridobi zapis ene ali obeh besed, ločenih z "|". Tu je primer prikazan pridobivanje dveh besed, ki sta prisotni v vseh datotekah imenika.
$ grep -I -E -w 'Aqsa | dobro' / domov / aqsayasin / datoteka *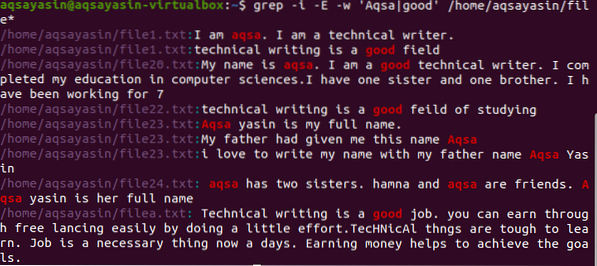
Zdaj izhod prikazuje obe besedi, ki sta prisotni v eni datoteki ali v različnih datotekah. Kot smo že omenili v imeniku, bomo dobili tudi imena datotek.
Uporaba '^ ()'
Tu '^ ()' deluje rekurzivno v primerjavi z zgornjim primerom."^" Prikazuje samo eno od dveh danih možnosti, tj.e., Aqsa in dobro, to je na prvem mestu v kateri koli datoteki. Izhod bo vseboval samo Aqso. Egrep je razširjeni regularni izraz.
$ egrep -I '^ (aqsa | dobro)' / home / aqsayasin / *.txt
Uporaba ^ $
Prikazuje ujemanje praznih / praznih nizov na koncu vrstice. Če je v besedilu prisotna vrzel, jo pridobi z naslednjim ukazom.
$ grep -n '^ $' / home / aqsayasin / *.txt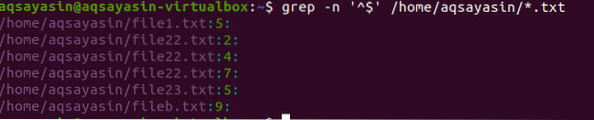
Iskane bodo vse besedilne datoteke. Izhod bo vseboval imena datotek in tudi številko vrstice, ki vsebuje prazen prostor v datoteki. V ukazu smo uporabili -n.

Uporaba []
Ta dva oklepaja prikazujeta, kako delujejo posebni znaki. [] vsebuje besedo za iskanje. Hkrati ujemanje v datoteki opišite N-krat. V nadaljevalnem primeru smo uporabili 2, ki prikazuje pojav vseh dveh možnih besed navedene besede v ukazu, ki je "the".
$ egrep '[the] 2' / home / aqsayasin / file *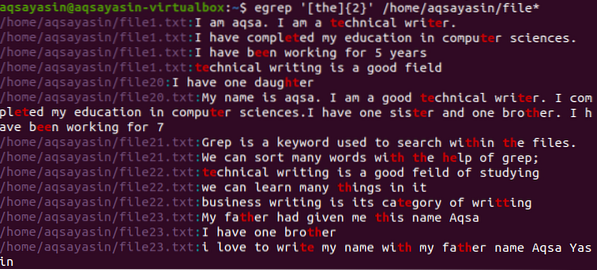
Zaključek
V članku, kot smo že omenili, smo obravnavali nekaj osnovnih primerov za razlago koncepta posebnih znakov v ukazu. Datoteko smo ustvarili in nato z uporabo ukaza grep pobrali podatke, ki so v njej. Upam, da boste po branju tega članka spoznali posebne znake, ki smo jih uporabili v našem članku.


