Sintaksa
$ grep 'pattern1 \ | pattern2' ime datotekeRegulalen izraz je vedno zapisan z enim samim navedkom. Dve imeni sta ločeni s poševnico nazaj in operaterjem spremembe. Ukaz se konča z imenom datoteke. Med izvajanjem grep-a rekurzivno se namesto enega imena datoteke uporablja imenik ali celotna pot.
Predpogoj
V tem članku bomo spoznali funkcionalnost grepa pri iskanju več vzorcev in nizov. V ta namen morate na svojem navideznem oknu zagnati operacijski sistem Linux. Namestiti ga morate v svoj sistem. Po konfiguraciji boste imeli dostop do vseh aplikacij. Po prijavi v uporabnika z vnosom gesla pojdite v ukazno vrstico lupine terminala, da nadaljujete.
Iskanje po več vzorcih v datoteki s pomočjo grepa
Če želimo v določeni datoteki iskati več vzorcev ali nizov, uporabite funkcijo grep za razvrščanje znotraj datoteke s pomočjo več kot ene vhodne besede v ukazu. Uporabljamo '\ |' operaterji za ločevanje dveh vzorcev v ukazu.
$ grep 'tehnična \ | naloga' datotekaa.txtUkaz predstavlja, kako grep deluje. Obe omenjeni datoteki bomo iskali v filea.txt. Iskane besede so označene v celotnem besedilu.

Če želimo poiskati več kot dve besedi, jih bomo še naprej dodajali na enak način.
$ grep 'graphic \ | photoshop \ | posters' datotekab.txt
Poiščite več nizov z ignoriranjem velikih in malih črk
Če želite razumeti koncept občutljivosti na male črke v funkciji grep v Linuxu, si oglejte naslednji primer. Dva ukaza delujeta na grep. Eno je z '-i', drugo pa brez. Ta primer prikazuje razlike med ukazi. Prva kaže, da bosta v določeni datoteki iskali dve besedi. Kakor pa je navedeno v ukazu “Aqsa”, se začne z veliko A. Tako ne bo poudarjeno, ker je to besedilo v določeni datoteki z malimi črkami.
$ grep 'Aqsa \ | sestrska' datoteka20.txtUpoštevala bo samo besedo sestra, ki bo vidna v rezultatih.
V drugem primeru smo z uporabo zastavice “-I” prezrli občutljivost na male in male črke. Ta funkcija bo iskala obe besedi in izhod bo poudarjen. Ne glede na to, ali je beseda 'Aqsa' napisana z velikimi tiskanimi črkami ali ne, bo grep iskal enako ujemanje v besedilu znotraj datoteke. Torej, oba ukaza sta si v pomoč.
$ grep -I 'Aqsa \ | sestrska' datoteka20.txt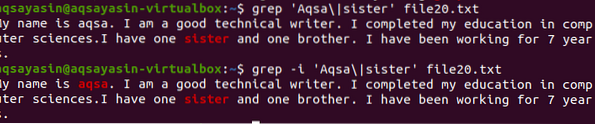
Štetje več zadetkov v datoteki
Funkcija štetja pomaga pri štetju pojavitve besede ali besed v določeni datoteki. Na primer, če želite vedeti o napakah, ki se pojavljajo v sistemu. Podrobnosti so zabeležene v datoteki dnevnikov. Če želite te podatke ohraniti v določeni mapi, boste zapisali pot map. Ta primer kaže, da je v dnevniških datotekah prišlo do 71 napak.

Poiščite natančna ujemanja v datoteki
Če želite v datotekah vašega sistema najti natančno ujemanje, morate za natančno razvrščanje uporabiti zastavico “-w”. Navedli smo preprost in izčrpen primer. V spodnjem primeru razmislite o iskanju brez “-w”, ta ukaz bo privedel obe besedi, kot se ujemata z danim vnosom. Toda z uporabo zastavice “-w” bo iskanje omejeno, saj se vhodne besede ujemajo samo s prvim nizom. Druga beseda ni označena, ker »-w« omogoča natančno ujemanje z vzorcem.
$ -iw 'hamna \ | house' datoteka21.txtTukaj -I se uporablja tudi za odstranjevanje občutljivosti na velike in male črke pri iskanju besedila.

Kot je razvidno na fotografiji, rezultati niso enaki. Prvi ukaz prinese vse povezane podatke s celimi nizi, drugi ukaz pa prikazuje, kako se natančni podatki ujemajo z grep pri iskanju več nizov.
Grep za več kot en vzorec v določeni vrsti razširitve datoteke
Iskanje poteka v vseh datotekah. Od vas je odvisno, ali boste iskali z navedbo imena datoteke. Iskali bodo samo v določenih datotekah. Toda z zagotavljanjem končnice datoteke bodo podatki iskani po vseh datotekah iste končnice. Obstajata dva različna primera, ki prikazujeta povezani rezultat. Glede na prvi primer se bodo datoteke z napakami štele v vse datoteke v .razširitev dnevnika. "-C" se uporablja za štetje.
$ grep -c 'opozorilo \ | napaka' / var / log / *.log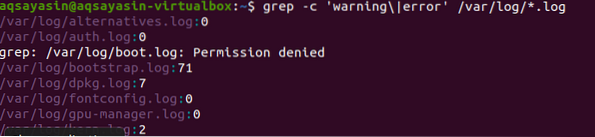
Ta ukaz pomeni, da bodo datoteke iskane v vseh datotekah .razširitev dnevnika. Število zadetkov bo prikazano v izhodu, da bo lažje prikazal grep s končnico datoteke.
V drugem primeru smo v datotekah v Linuxu z razširitvijo besedila uporabili dve besedi. Vsi podatki bodo prikazani v obliki številk. 0 pomeni, da ni ujemajočih se podatkov, medtem ko drugače od 0 kaže, da ujemanje obstaja.
$ grep -c 'aqsa \ | my' / home / aqsayasin / *.txt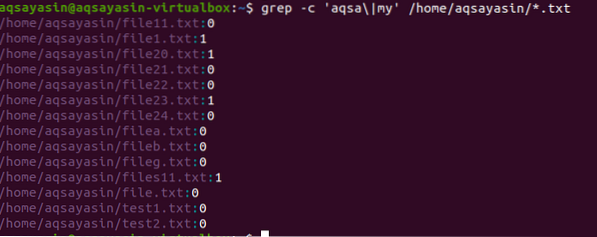
Rekurzivno iskanje več vzorcev v datoteki
Privzeto se uporablja trenutni imenik, če v ukazu ni nobenega imenika. Če želite iskati v imeniku po lastni izbiri, ga morate omeniti. Operator -r se uporablja za grep rekurzivno./ home / aqsayasin / prikazuje pot datotek, medtem ko *.txt prikazuje razširitev. Besedilne datoteke bodo cilj grepa za rekurzivno iskanje.
$ grep -R 'tehnični \ | brezplačno' / home / aqsayasin / *.txt
Želeni izhod je poudarjen v rezultatu, ki prikazuje obstoj teh besed.
Zaključek
V zgoraj omenjenem članku smo navedli različne primere, da uporabnik lažje razume delovanje ukazov za iskanje po več vzorcih v Linuxu. Ta vodnik vam bo pomagal pri stopnjevanju obstoječega znanja.


