TensorFlow je našel izjemno uporabo na področju strojnega učenja, ravno zato, ker strojno učenje vključuje veliko drobljenja števil in se uporablja kot splošna tehnika reševanja problemov. In čeprav bomo z njim komunicirali s pomočjo Pythona, ima prednje konce za druge jezike, kot je Go, Node.js in celo C #.
Tensorflow je kot črna škatla, ki v sebi skriva vse matematične prefinjenosti, razvijalec pa samo pokliče prave funkcije za rešitev problema. Toda kakšen problem?
Strojno učenje (ML)
Recimo, da načrtujete bota za igranje šaha. Zaradi načina oblikovanja šaha, premikanja figur in natančno določenega cilja igre je povsem mogoče napisati program, ki bi igro izredno dobro igral. Pravzaprav bi v šahu prelisičil celotno človeško vrsto. Natančno bi vedel, kakšen korak mora narediti glede na stanje vseh kosov na plošči.
Vendar lahko tak program igra samo šah. Pravila igre so vpeta v logiko kode in vse, kar program naredi, je, da to logiko izvaja strogo in natančneje, kot bi lahko kdorkoli. To ni splošni algoritem, ki bi ga lahko uporabili za načrtovanje katerega koli bota za igre.
S strojnim učenjem se paradigma spremeni in algoritmi postajajo vse bolj splošni.
Ideja je preprosta, začne se z opredelitvijo problema s klasifikacijo. Na primer, želite avtomatizirati postopek prepoznavanja vrst pajkov. Vrste, ki so vam znane, so različni razredi (ne smemo jih zamenjati s taksonomskimi razredi), cilj algoritma pa je razvrstiti novo neznano sliko v enega od teh razredov.
Tu bi bil prvi korak za človeka določitev značilnosti različnih posameznih pajkov. Posredovali bi podatke o dolžini, širini, telesni masi in barvi posameznih pajkov skupaj z vrstami, ki jim pripadajo:
| Dolžina | Premer | Maša | Barva | Tekstura | Vrste |
| 5 | 3 | 12 | rjav | gladko | Očka Dolge noge |
| 10 | 8 | 28 | Rjavo-črna | kosmat | Tarantula |
Obsežna zbirka takih posameznih podatkov o pajkih bo uporabljena za "treniranje" algoritma, druga podobna zbirka podatkov pa bo uporabljena za testiranje algoritma, da se ugotovi, kako uspešen je glede na nove informacije, s katerimi se še ni srečal, vendar jih že poznamo. odgovoriti na.
Algoritem se bo začel naključno. Se pravi, da bi bil vsak pajek, ne glede na njegove značilnosti, uvrščen med katere koli vrste. Če je v našem naboru podatkov 10 različnih vrst, bi bil ta naivni algoritem približno 1/10 časa zaradi pravilne sreče pravilno razvrščen.
Potem pa bi začel prevzeti vidik strojnega učenja. Nekatere značilnosti bi začelo povezovati z določenim izidom. Na primer, dlakavi pajki so verjetno tarantule, prav tako pa tudi večji pajki. Torej, kadar koli se pojavi nov pajek, ki je velik in poraščen, mu bo dodeljena večja verjetnost, da bo tarantula. Opazite, še vedno delamo z verjetnostmi, ker sami po sebi delamo z verjetnostnim algoritmom.
Učni del deluje tako, da spreminja verjetnosti. Sprva algoritem začne z naključnim dodeljevanjem oznak "vrsta" posameznikom z naključnimi korelacijami, kot so "kosmat" in "očka dolge noge". Ko naredi takšno korelacijo in se zdi, da se nabor podatkov o vadbi z njo ne strinja, se ta predpostavka zavrne.
Podobno, ko korelacija dobro deluje na več primerih, je vsakič močnejša. Ta metoda spotikanja do resnice je izjemno učinkovita, zahvaljujoč številnim matematičnim prefinjenostim, zaradi katerih kot začetnik ne bi želeli skrbeti.
TensorFlow in trenirajte svoj lastni klasifikator cvetov
TensorFlow idejo o strojnem učenju popelje še dlje. V zgornjem primeru ste bili odgovorni za določanje lastnosti, ki ločujejo eno vrsto pajka od druge. Morali smo skrbno izmeriti posamezne pajke in ustvariti na stotine takih zapisov.
Lahko pa boljše, če algoritmu zagotovimo samo surove slikovne podatke, lahko mu omogočimo, da najde vzorce in razume različne stvari na sliki, na primer prepoznavanje oblik na sliki, nato razumevanje, kakšna je tekstura različnih površin, barva , tako naprej in tako naprej. To je začetni pojem računalniškega vida in ga lahko uporabite tudi za druge vhode, kot so zvočni signali in urjenje algoritma za prepoznavanje glasu. Vse to spada pod krovni izraz "poglobljeno učenje", kjer je strojno učenje prišlo do svoje logične skrajnosti.
Ta splošni sklop pojmov je nato mogoče specializirati za obravnavo številnih podob rož in njihovo kategorizacijo.
V spodnjem primeru bomo uporabili Python2.7 front-end za vmesnik s TensorFlow in za namestitev TensorFlowa bomo uporabili pip (ne pip3). Podpora za Python 3 je še vedno nekoliko napačna.
Če želite narediti svoj lastni klasifikator slik, ga najprej uporabite z uporabo TensorFlowa pip:
$ pip namesti tensorflowNato moramo klonirati tensorflow-za-pesnike-2 git repozitorij. To je res dober kraj za začetek iz dveh razlogov:
- Je preprost in enostaven za uporabo
- Do določene mere je predhodno usposobljen. Na primer, klasifikator cvetov je že usposobljen, da razume, kakšno strukturo gleda in katere oblike gleda, zato je računsko manj intenziven.
Pridobimo repozitorij:
$ git klon https: // github.com / googlecodelabs / tensorflow-for-poets-2$ cd tensorflow-za-pesnike-2
To bo naš delovni imenik, zato naj bodo odslej vsi ukazi izdani znotraj njega.
Še vedno moramo izuriti algoritem za specifičen problem prepoznavanja cvetja, za to potrebujemo podatke o treningu, zato poglejmo naslednje:
$ curl http: // prenos.tensorflow.org / example_images / flower_photos.tgz| tar xz -C tf_files
Imenik .. ./tensorflow-for-poets-2 / tf_files vsebuje tono teh slik, ki so pravilno označene in pripravljene za uporabo. Slike bodo za dva različna namena:
- Usposabljanje za program ML
- Testiranje programa ML
Vsebino mape lahko preverite tf_files in tu boste ugotovili, da se zožujemo na samo 5 kategorij cvetov, in sicer marjetice, tulipani, sončnice, regrat in vrtnice.
Izobraževanje modela
Postopek vadbe lahko začnete tako, da najprej nastavite naslednje konstante za spreminjanje velikosti vseh vhodnih slik v standardno velikost in uporabite lahko arhitekturo mobilne mreže:
$ IMAGE_SIZE = 224$ ARCHITECTURE = "mobilenet_0.50 _ $ IMAGE_SIZE "
Nato pokličite skript python z zagonom ukaza:
$ python -m skripte.prekvalificirati \--ozko grlo = tf_files / ozka grla \
--how_many_training_steps = 500 \
--model_dir = tf_files / models / \
--summaries_dir = tf_files / training_summaries / "$ ARCHITECTURE" \
--output_graph = tf_files / retrained_graph.pb \
--output_labels = tf_files / retrained_labels.txt \
--arhitektura = "$ ARCHITECTURE" \
--image_dir = tf_files / flower_photos
Čeprav je tu določenih veliko možnosti, večina določa vaše imenike vhodnih podatkov in število ponovitev ter izhodne datoteke, v katere bi bile shranjene informacije o novem modelu. To ne bi smelo trajati dlje kot 20 minut, da bi se zagnali na povprečnem prenosniku.
Ko skript konča tako usposabljanje kot preskušanje, vam bo dal oceno natančnosti izurjenega modela, ki je bila v našem primeru nekoliko višja od 90%.
Uporaba usposobljenega modela
Zdaj ste pripravljeni na uporabo tega modela za prepoznavanje slik katere koli nove podobe rože. Uporabili bomo to sliko:

Obraz sončnice je komaj viden in to je velik izziv za naš model:
Če želite to sliko dobiti iz Wikimedia commons, uporabite wget:
$ wget https: // upload.wikimedia.org / wikipedia / commons / 2/28 / Sunflower_head_2011_G1.jpg$ mv Sunflower_head_2011_G1.jpg tf_files / neznano.jpg
Shrani se kot neznano.jpg pod tf_files podimenik.
Zdaj, za trenutek resnice, bomo videli, kaj bo naš model povedal o tej podobi.Za to pokličemo slika_nalepke scenarij:
$ python -m skripte.label_image --graph = tf_files / retrained_graph.pb --image = tf_files / neznano.jpg
Dobili bi izhod, podoben temu:
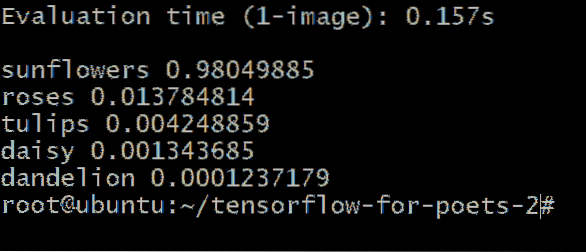
Številke poleg vrste cvetov predstavljajo verjetnost, da naša neznana slika spada v to kategorijo. Na primer, 98.04% je prepričanih, da je slika sončnice in je samo 1.37-odstotna verjetnost, da gre za vrtnico.
Zaključek
Tudi pri zelo povprečnih računskih virih opažamo neverjetno natančnost pri prepoznavanju slik. To jasno dokazuje moč in prilagodljivost sistema TensorFlow.
Od tu naprej lahko začnete eksperimentirati z različnimi drugimi vrstami vhodov ali poskusite začeti pisati svojo različno aplikacijo s pomočjo Python in TensorFlow. Če želite malo bolje poznati notranje delovanje strojnega učenja, je to interaktiven način.


