Ta pregled je nekoliko abstrakten, zato ga utemeljimo v resničnem scenariju, predstavljajmo si, da morate spremljati več spletnih strežnikov. Vsak ima svoje spletno mesto, v vsaki od njih pa se vsako sekundo dneva nenehno ustvarjajo novi dnevniki. Poleg tega obstaja še nekaj e-poštnih strežnikov, ki jih morate tudi spremljati.
Te podatke boste morda morali shraniti za vodenje evidence in zaračunavanje, kar je paketno opravilo, ki ne zahteva takojšnje pozornosti. Morda boste želeli zagnati analitiko podatkov, da boste lahko v realnem času sprejemali odločitve, ki zahtevajo natančen in takojšen vnos podatkov. Nenadoma se znajdete v potrebi po racionalizaciji podatkov na razumen način za vse različne potrebe. Kafka deluje kot tista plast abstrakcije, ki ji lahko več virov objavi različne tokove podatkov in dano potrošnik se lahko naročite na tokove, ki se jim zdijo pomembni. Kafka bo poskrbel, da bodo podatki dobro urejeni. Kafkine notranje elemente moramo razumeti, preden pridemo do teme razdelitve in tipk.
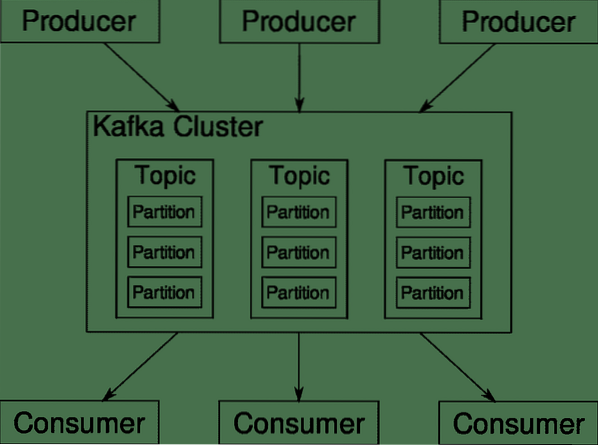
Teme Kafka, posrednik in predelne stene
Kafka Teme so kot tabele baze podatkov. Vsaka tema je sestavljena iz podatkov iz določenega vira določene vrste. Na primer, zdravje vaše gruče je lahko tema, ki jo sestavljajo informacije o uporabi procesorja in pomnilnika. Podobno je lahko dohodni promet prek celotne gruče druga tema.
Kafka je zasnovana tako, da je vodoravno prilagodljiva. Se pravi, da en sam primer Kafke sestavlja več Kafk posredniki teče čez več vozlišč, lahko vsako obravnava tokove podatkov vzporedno drugemu. Tudi če nekaj vozlišč ne uspe, lahko vaš podatkovni cevovod še naprej deluje. Nato lahko določeno temo razdelimo na več predelne stene. Ta razdelitev je eden ključnih dejavnikov za horizontalno razširljivost Kafke.
Večkraten proizvajalci, viri podatkov za določeno temo, lahko istočasno pišejo v to temo, ker vsak na kateri koli točki piše na drugo particijo. Zdaj se particiji običajno podatki dodelijo naključno, razen če ji nudimo ključa.
Pregraditev in urejanje
Samo za povzetek, proizvajalci pišejo podatke na določeno temo. Ta tema je dejansko razdeljena na več particij. In vsaka particija živi neodvisno od drugih, tudi za določeno temo. To lahko povzroči veliko zmedo, ko je vrstni red podatkov pomemben. Morda potrebujete podatke v kronološkem vrstnem redu, vendar več particij za vaš podatkovni tok ne zagotavlja popolnega razvrščanja.
Za vsako temo lahko uporabite samo eno particijo, vendar to premaga celoten namen Kafkine porazdeljene arhitekture. Torej potrebujemo neko drugo rešitev.
Tipke za particije
Podatki proizvajalca se na particije pošljejo naključno, kot smo že omenili. Sporočila so dejanski deli podatkov. Proizvajalci lahko poleg pošiljanja sporočil dodajo ključ, ki je zraven.
Vsa sporočila, priložena določenemu ključu, bodo šla na isto particijo. Tako lahko na primer dejavnost uporabnika kronološko sledimo, če so podatki tega uporabnika označeni s ključem in tako vedno končajo na eni particiji. Poimenujmo to particijo p0 in uporabnika u0.
Razdelek p0 bo vedno pobral sporočila, povezana z u0, ker jih ta ključ poveže. Toda to ne pomeni, da je p0 vezan samo na to. Sporočila lahko sprejme tudi od u1 in u2, če ima to zmožnost. Podobno lahko druge particije porabijo podatke drugih uporabnikov.
Točka, da se podatki uporabnika ne razširijo na različne particije, kar zagotavlja kronološko razvrščanje za tega uporabnika. Vendar pa je splošna tema uporabniške podatke, še vedno lahko izkoristi porazdeljeno arhitekturo Apache Kafke.
Zaključek
Medtem ko porazdeljeni sistemi, kot je Kafka, rešujejo nekatere starejše težave, na primer pomanjkanje razširljivosti ali eno samo točko okvare. Imajo vrsto težav, ki so značilne samo za njihov dizajn. Predvidevanje teh težav je bistvena naloga vsakega sistemskega arhitekta. Ne samo to, včasih morate res narediti analizo stroškov in koristi, da ugotovite, ali so novi problemi vreden kompromis, da se znebite starejših. Naročanje in sinhronizacija sta le vrh ledene gore.
Upamo, da vam bodo takšni članki in uradna dokumentacija lahko v pomoč.


