Upoštevajte, da to ni uvodna lekcija. Prosimo, preberite Kaj je Apache Kafka in kako deluje, preden nadaljujete s to lekcijo in pridobite globlji vpogled.
Teme v Kafki
Tema v Kafki je nekaj, kamor se pošlje sporočilo. Potrošniške aplikacije, ki jih ta tema zanima, povlečejo sporočilo v to temo in s temi podatki lahko storijo karkoli. Do določenega časa lahko poljubno število potrošniških aplikacij to sporočilo potegne poljubno številokrat.
Razmislite o temi, kot je spletna stran Ubuntu o LinuxHintu. Lekcije so postavljene do večnosti in poljubno število bralcev navdušencev lahko pride in jih prebere poljubno številokrat ali se premakne na naslednjo lekcijo, kot želi. Te bralce lahko zanimajo tudi druge teme iz LinuxHinta.
Delitev teme
Kafka je zasnovan za upravljanje težkih aplikacij in čakanje velikega števila sporočil v temo. Da bi zagotovili visoko odpornost na napake, je vsaka tema razdeljena na več particij teme in vsaka particija teme upravlja na ločenem vozlišču. Če se eno od vozlišč spusti, lahko drugo vozlišče deluje kot vodja tem in lahko teme streži zainteresiranim potrošnikom. Evo, kako se isti podatki zapisujejo v več particij tem: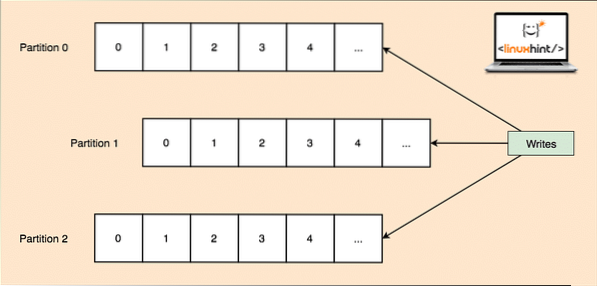
Tematske particije
Zdaj zgornja slika prikazuje, kako se isti podatki replicirajo na več particijah. Predstavljajmo si, kako lahko različne particije delujejo kot vodja na različnih vozliščih / particijah:
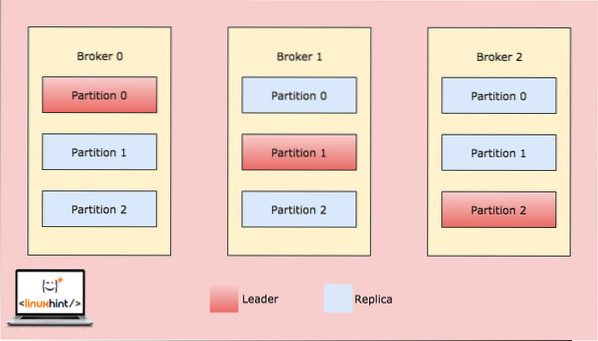
Kafka Broker Partitioning
Ko odjemalec kaj zapiše v temo na položaju, pri katerem je particija v posredniku 0 vodilna, se ti podatki nato kopirajo med posredniki / vozlišči, tako da ostane sporočilo varno: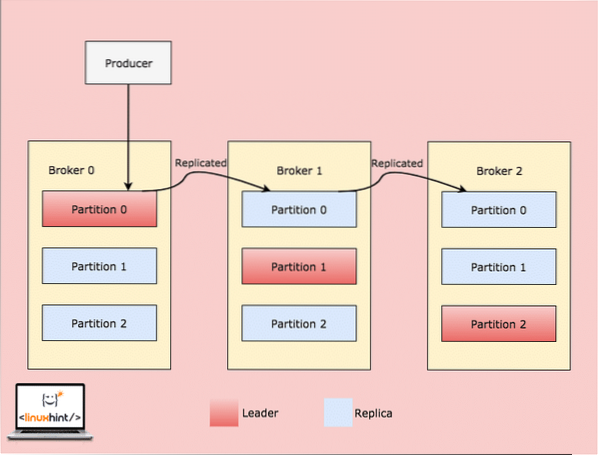
Replikacija na posredniške particije
Več particij, večja prepustnost
Kafka uporablja Vzporednost zagotoviti zelo visoko prepustnost za aplikacije proizvajalcev in potrošnikov. Pravzaprav na enak način ohranja tudi status visoko odpornega sistema. Razumejmo, kako visoko zmogljivost dosežemo z vzporednostjo.
Ko aplikacija Producer na particijo v Broker 0 napiše nekaj sporočil, Kafka vzporedno odpre več niti, tako da lahko sporočilo istočasno replicira v vseh izbranih posrednikih. Na strani Potrošnik potrošniška aplikacija porabi sporočila z ene particije skozi nit. Več kot je particij, več potrošniških niti je mogoče odpreti, tako da lahko delujejo tudi vse vzporedno. To pomeni, da bolj kot je število particij v gruči, več vzporednosti je mogoče izkoristiti in ustvariti zelo visok pretočni sistem.
Več particij potrebuje več datotek
Samo zato, da ste zgoraj preučili, kako lahko povečamo zmogljivost sistema Kafka samo s povečanjem števila particij. Toda previdni moramo biti pri tem, do katere meje gremo.
Vsaka tematska particija v Kafki se preslika v imenik v datotečnem sistemu posrednika strežnikov, kjer se izvaja. V tem imeniku dnevnika bosta dve datoteki: ena za indeks in druga za dejanske podatke na segment dnevnika. Trenutno v Kafki vsak posrednik odpre ročico datoteke tako za indeks kot za podatkovno datoteko vsakega segmenta dnevnika. To pomeni, da če imate na enem posredniku 10.000 particij, bo vzporedno teklo 20.000 datotek. Čeprav gre zgolj za konfiguracijo posrednika. Če ima sistem, v katerem je posrednik postavljen, visoko konfiguracijo, to težko predstavlja težavo.
Tveganje z velikim številom particij
Kot smo videli na zgornjih slikah, Kafka uporablja tehniko replikacije znotraj grozda za kopiranje sporočila vodje na particije Replica, ki ležijo v drugih posrednikih. Tako proizvajalčeva kot potrošniška aplikacija bereta in pišeta na particijo, ki je trenutno vodja te particije. Ko posrednik ne uspe, vodja tega posrednika ne bo na voljo. Metapodatki o tem, kdo je vodja, se hranijo v Zookeeperju. Na podlagi teh metapodatkov bo Kafka samodejno dodelil vodenje particije drugi particiji.
Ko je posrednik zaustavljen s čistim ukazom, bo vozlišče krmilnika grozda Kafka serijsko premaknilo vodje izklopa posrednika i.e. enega za drugim. če menimo, da premikanje enega voditelja traja 5 milisekund, nerazpoložljivost voditeljev ne bo motila potrošnikov, saj je nedostopnost zelo kratka. Če pa pomislimo, kdaj je posrednik ubit na nečist način in ta posrednik vsebuje 5000 particij, od tega je bilo 2000 voditeljev particij, bo dodelitev novih voditeljev za vse te particije trajalo 10 sekund, kar je zelo visoko, ko gre za zelo aplikacije na zahtevo.
Zaključek
Če mislimo, da mislimo na visoki ravni, več razdelkov v grozdu Kafka vodi do večje prepustnosti sistema. Upoštevajoč to učinkovitost moramo upoštevati tudi konfiguracijo grozda Kafka, ki jo moramo vzdrževati, pomnilnik, ki ga moramo dodeliti tej grozdi, in kako lahko upravljamo razpoložljivost in zakasnitev, če gre kaj narobe.
Preberite več objav na osnovi Ubuntuja in še veliko več o Apache kafki.


