Veliki podatki so podatki v vrstnem redu terabajtov ali petabajtov in več, ki vključujejo rudarjenje, analizo in napovedno modeliranje velikih naborov podatkov. Hitra rast informacijskega in tehnološkega razvoja je zagotovila edinstveno priložnost za posameznike in podjetja po vsem svetu, da ustvarijo dobiček in razvijejo nove zmogljivosti, ki na novo opredeljujejo tradicionalne poslovne modele z uporabo obsežne analitike.
Ta članek ponuja pogled iz ptičje perspektive na pet najbolj priljubljenih odprtokodnih podatkovnih platform. Tu je naš seznam:
Apache Hadoop
Apache Hadoop je odprtokodna programska platforma, ki obdeluje zelo velike nabore podatkov v porazdeljenem okolju glede na pomnilniško in računsko moč in je v glavnem zgrajena na nizkocenovni osnovni strojni opremi.
Apache Hadoop je zasnovan za enostavno razširitev od nekaj do tisoč strežnikov. Pomaga vam pri obdelavi lokalno shranjenih podatkov v splošni nastavitvi vzporedne obdelave. Ena od prednosti Hadoopa je, da odpravlja okvare na programski ravni. Naslednja slika prikazuje splošno arhitekturo ekosistema Hadoop in kje so znotraj njega različni okviri:
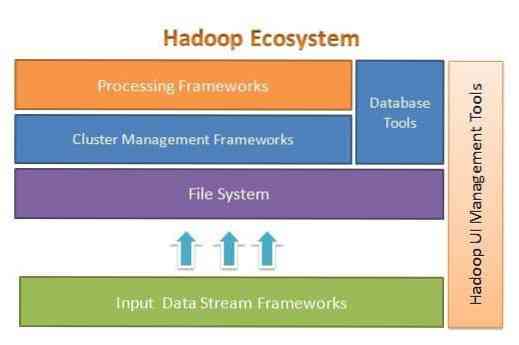
Apache Hadoop ponuja ogrodje za plast datotečnega sistema, plast za upravljanje gruč in plast obdelave. Pusti možnost, da drugi projekti in okviri sodelujejo skupaj z ekosistemom Hadoop in razvijejo lasten okvir za katero koli plast, ki je na voljo v sistemu.
Apache Hadoop je sestavljen iz štirih glavnih modulov. Ti moduli so Hadoop Distributed File System (plast datotečnega sistema), Hadoop MapReduce (ki deluje tako z upravljanjem gruče kot s plastjo obdelave), Yet Another Resource Negotiator (YARN, plast upravljanja gruč) in Hadoop Common.
Elasticsearch
Elasticsearch je popoln besedilni mehanizem za iskanje in analitiko. Je zelo razširljiv in porazdeljen sistem, posebej zasnovan za učinkovito in hitro delo s sistemi velikih podatkov, kjer je eden glavnih primerov uporabe analiza dnevnikov. Sposoben je izvajati napredna in zapletena iskanja ter skoraj sprotno obdelavo napredne analitike in operativne inteligence.
Elasticsearch je napisan v Javi in temelji na Apache Lucene. Izdan leta 2010 in je hitro pridobil priljubljenost zaradi prilagodljive strukture podatkov, prilagodljive arhitekture in zelo hitrega odzivnega časa. Elasticsearch temelji na dokumentu JSON s strukturo brez shem, kar olajša posvojitev in brez težav. Je eden najboljših iskalnikov poslovnega razreda. Njenega odjemalca lahko napišete v katerem koli programskem jeziku; Elasticsearch uradno deluje z Javo, .NET, PHP, Python, Perl itd.
Elasticsearch večinoma komunicira z uporabo API-ja REST. Podatke dobi v obliki dokumentov JSON z vsemi zahtevanimi parametri in podobno odgovori.
MongoDB
MongoDB je baza podatkov NoSQL, ki temelji na podatkovnem modelu shrambe dokumentov. V MongoDB je vse bodisi zbirka bodisi dokument. Da bi razumeli terminologijo MongoDB, je zbirka nadomestna beseda za tabelo, medtem ko je dokument nadomestna beseda za vrstice.
MongoDB je odprtokodna, v dokumente usmerjena in večplastna baza podatkov. Pisano je predvsem v jeziku C++. Je tudi vodilna baza podatkov NoSQL, ki zagotavlja visoko zmogljivost, visoko razpoložljivost in enostavno razširljivost. MongoDB uporablja JSON-podobne dokumente s shemo in ponuja bogato podporo za poizvedbe. Nekatere glavne funkcije vključujejo indeksiranje, kopiranje, uravnoteženje obremenitve, združevanje in shranjevanje datotek.
Cassandra
Cassandra je odprtokodni projekt Apache, zasnovan za upravljanje baz podatkov NoSQL. Vrstice Cassandra so razporejene v tabele in indeksirane s ključem. Uporablja mehanizem za shranjevanje, ki temelji na dnevniku in je samo dodatek. Podatki v Cassandri se porazdelijo po več vozliščih brez master-a, brez ene same točke okvare. Gre za projekt Apache najvišje ravni, njegov razvoj pa trenutno nadzira Fundacija Apache Software Foundation (ASF).
Cassandra je zasnovana za reševanje težav, povezanih z delovanjem v velikem (spletnem) obsegu. Glede na brezkonstrukturno arhitekturo Cassandre lahko kljub majhnemu (čeprav znatnemu) številu okvar strojne opreme še naprej izvaja operacije. Cassandra teče čez več vozlišč v več podatkovnih centrih. Podvaja podatke v teh podatkovnih centrih, da se izogne okvaram ali izpadom. Zaradi tega je sistem zelo odporen na napake.
Cassandra za dostop do podatkov prek svojih vozlišč uporablja svoj programski jezik. Imenuje se Cassandra Query Language ali CQL. Podoben je SQL-u, ki ga v glavnem uporabljajo relacijske zbirke podatkov. CQL lahko uporabite tako, da zaženete lastno aplikacijo, imenovano cqlsh. Cassandra ponuja tudi številne integracijske vmesnike za več programskih jezikov za izdelavo aplikacije z uporabo Cassandre. Njegov integracijski API podpira Java, C ++, Python in druge.
Apache HBase
HBase je še en projekt Apache, zasnovan za upravljanje shrambe podatkov NoSQL. Zasnovan je tako, da uporablja funkcije ekosistema Hadoop, vključno z zanesljivostjo, odpornostjo na napake itd. HDFS uporablja kot datotečni sistem za namene shranjevanja. NoSQL deluje z več podatkovnimi modeli, Apache HBase pa spada v stolpčno usmerjen podatkovni model. HBase je prvotno temeljil na Google Big Table, ki je povezan tudi s stolpčno usmerjenim modelom za nestrukturirane podatke.
HBase shrani vse v obliki para ključ-vrednost. Pomembno je omeniti, da sta v HBase ključ in vrednost v obliki bajtov. Za shranjevanje kakršnih koli informacij v HBase morate podatke pretvoriti v bajte. (Z drugimi besedami, njegov API ne sprejema ničesar drugega kot bajtno matriko.) Bodite previdni pri uporabi HBase, saj morate pri shranjevanju podatkov zapomniti prvotno vrsto. Podatki, ki so bili prvotno niz, se vrnejo kot bajtna matrika, če jih nepravilno prikličete. Posledično bo ustvaril napako v vaši aplikaciji in zrušil vašo aplikacijo.
Upam, da vam je bil članek všeč. Če želite oblikovati in oblikovati podatkovno intenzivne aplikacije, lahko raziščete Anuja Kumarja Arhitektura podatkovno intenzivnih aplikacij. To knjigo je vaš prehod za izgradnjo pametnih podatkovno intenzivnih sistemov z vključitvijo temeljnih podatkovno intenzivnih arhitekturnih načel, vzorcev in tehnik neposredno v vašo aplikacijsko arhitekturo.

