V tej lekciji o strojnem učenju s scikit-learn bomo spoznali različne vidike tega odličnega paketa Python, ki nam omogoča uporabo enostavnih in zapletenih zmogljivosti strojnega učenja na raznolikih naborih podatkov skupaj s funkcionalnostmi za preizkušanje hipoteze, ki jo ugotovimo.
Paket scikit-learn vsebuje preprosta in učinkovita orodja za uporabo podatkovnega rudarjenja in analize podatkov na naborih podatkov, ti algoritmi pa so na voljo za uporabo v različnih kontekstih. Gre za odprtokodni paket, ki je na voljo pod licenco BSD, kar pomeni, da lahko to knjižnico uporabljamo celo komercialno. Zgrajen je na vrhu matplotlib, NumPy in SciPy, zato je vsestranske narave. Za predstavitev primerov v tej lekciji bomo uporabili Anacondo z zvezkom Jupyter.
Kaj ponuja scikit-learn?
Knjižnica scikit-learn se popolnoma osredotoča na modeliranje podatkov. Prosimo, upoštevajte, da pri nalaganju, manipulaciji in povzetku podatkov v scikit-learnu ni večjih funkcij. Tu je nekaj priljubljenih modelov, ki nam jih ponuja scikit-learn:
- Grozdenje združiti označene podatke
- Nabori podatkov zagotoviti preskusne nize podatkov in raziskati vedenje modelov
- Navzkrižno potrjevanje za oceno uspešnosti nadzorovanih modelov na nevidnih podatkih
- Ansambelske metode kombiniranju napovedi več nadzorovanih modelov
- Izvleček lastnosti do določanja atributov v slikovnih in besedilnih podatkih
Namestite Python scikit-learn
Samo opomba pred začetkom namestitvenega postopka za to lekcijo uporabljamo navidezno okolje, ki smo ga naredili z naslednjim ukazom:
python -m virtualenv scikitizvor scikit / bin / activate
Ko je navidezno okolje aktivno, lahko v navidezno env namestimo knjižnico pand, da lahko izvajamo primere, ki jih ustvarimo v naslednjem primeru:
pip namestite scikit-learnLahko pa s Condo namestimo ta paket z naslednjim ukazom:
conda namestite scikit-learnNekaj takega vidimo, ko izvršimo zgornji ukaz:

Ko se namestitev konča s Condo, bomo paket v naših skriptih Python lahko uporabljali kot:
uvoz sklearnZačnimo uporabljati scikit-learn v naših skriptah za razvoj odličnih algoritmov strojnega učenja.
Uvoz podatkovnih nizov
Ena od kul stvari pri scikit-learn je, da je prednaložena z vzorčnimi nabori podatkov, s katerimi je enostavno hitro začeti. Nabori podatkov so iris in števke podatkovni nizi za razvrščanje in cene stanovanj v bostonu nabor podatkov za regresijske tehnike. V tem poglavju bomo preučili, kako naložiti in začeti uporabljati nabor podatkov irisa.
Za uvoz nabora podatkov moramo najprej uvoziti pravi modul, čemur je sledilo zadrževanje nabora podatkov:
iz sklopov podatkov za uvoz sklearniris = nabori podatkov.load_iris ()
številke = nabori podatkov.load_digits ()
števke.podatkov
Ko zaženemo zgornji delček kode, bomo videli naslednji izhod:

Ves izhod se odstrani za kratkost. To je nabor podatkov, ki ga bomo v glavnem uporabljali v tej lekciji, vendar je večino konceptov mogoče uporabiti na splošno za vse nabore podatkov.
Prav zabavno dejstvo je vedeti, da je v modulu več modulov scikit ekosistem, eden izmed njih je naučiti se uporablja se za algoritme strojnega učenja. Oglejte si to stran za številne druge prisotne module.
Raziskovanje nabora podatkov
Zdaj, ko smo v naš skript uvozili nabor podatkov s številkami, bi morali začeti zbirati osnovne informacije o naboru podatkov in to bomo storili tukaj. Tu so osnovne stvari, ki jih morate raziskati, ko iščete informacije o naboru podatkov:
- Ciljne vrednosti ali oznake
- Atribut opisa
- Ključi, ki so na voljo v danem naboru podatkov
Zapišemo kratek delček kode, da bomo iz našega nabora podatkov izvlekli zgornje tri informacije:
print ('Cilj:', števke.cilj)print ('Tipke:', števke.tipke ())
print ('Opis:', števke.DESCR)
Ko zaženemo zgornji delček kode, bomo videli naslednji izhod:
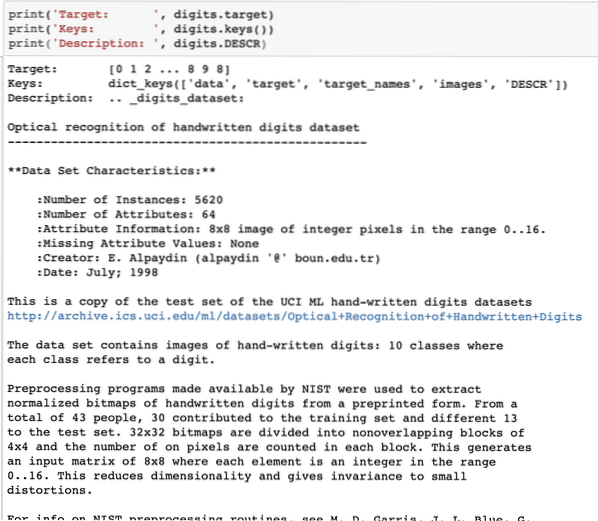
Upoštevajte, da spremenljive številke niso enostavne. Ko smo natisnili številčni nabor podatkov, je dejansko vseboval številska polja. Videli bomo, kako lahko dostopamo do teh nizov. Za to si oglejte tipke, ki so na voljo v primerku števk, ki smo ga natisnili v zadnjem delčku kode.
Začeli bomo z oblikovanjem podatkov o matriki, to so vrstice in stolpci, ki jih ima matrika. Za to moramo najprej dobiti dejanske podatke, nato pa še njihovo obliko:
digits_set = števke.podatkovtiskanje (nabor številk.oblika)
Ko zaženemo zgornji delček kode, bomo videli naslednji izhod:

To pomeni, da imamo v našem naboru podatkov 1797 vzorcev skupaj s 64 podatkovnimi funkcijami (ali stolpci). Prav tako imamo nekaj ciljnih nalepk, ki jih bomo tukaj vizualizirali s pomočjo matplotlib. Tu je delček kode, ki nam pomaga, da to storimo:
uvozi matplotlib.pyplot kot plt# Slike in ciljne nalepke združite kot seznam
images_and_labels = seznam (zip (števke.slike, številke.cilj))
za indeks, (slika, nalepka) v enumerate (images_and_labels [: 8]):
# inicializirajte podplos 2X4 na i + 1-jem mestu
plt.subplot (2, 4, index + 1)
# Ni treba risati nobene osi
plt.os ('izključeno')
# Prikaži slike v vseh podploskah
plt.imshow (slika, cmap = plt.cm.grey_r, interpolacija = 'najbližje')
# Vsakemu podplohu dodajte naslov
plt.title ('Usposabljanje:' + str (nalepka))
plt.pokaži ()
Ko zaženemo zgornji delček kode, bomo videli naslednji izhod:

Upoštevajte, kako smo stisnili dve matriki NumPy skupaj, preden smo jih narisali v mrežo 4 x 2 brez kakršnih koli informacij o oseh. Zdaj smo prepričani o informacijah, ki jih imamo o naboru podatkov, s katerimi delamo.
Zdaj, ko vemo, da imamo 64 podatkovnih funkcij (kar je sicer veliko funkcij), je težko vizualizirati dejanske podatke. Za to imamo rešitev.
Analiza glavne komponente (PCA)
To ni vadnica o PCA, vendar si oglejmo, kaj je. Ker vemo, da imamo za zmanjšanje števila funkcij iz nabora podatkov dve tehniki:
- Odprava lastnosti
- Izvleček funkcije
Medtem ko se prva tehnika sooča z vprašanjem izgubljenih podatkovnih funkcij, četudi so bile morda pomembne, druga tehnika ne trpi zaradi težave, saj s pomočjo PCA oblikujemo nove podatkovne funkcije (manj jih je), kjer kombiniramo vhodne spremenljivke na tak način, da lahko izpustimo "najmanj pomembne" spremenljivke, hkrati pa ohranimo najdragocenejše dele vseh spremenljivk.
Kot je bilo pričakovano, PCA nam pomaga zmanjšati visoko dimenzionalnost podatkov kar je neposreden rezultat opisa predmeta z uporabo številnih podatkovnih funkcij. Ne samo številke, temveč tudi številni drugi praktični nabori podatkov imajo veliko število funkcij, ki vključujejo finančne institucionalne podatke, podatke o vremenu in gospodarstvu za regijo itd. Ko izvedemo PCA na naboru številk, naš cilj bo najti le dve lastnosti, ki imata večino značilnosti nabora podatkov.
Napišimo preprost delček kode, s katerim bomo uporabili PCA na naboru številk, da bomo dobili naš linearni model samo dveh lastnosti:
iz sklearn.razgradnja uvoz PCAfeature_pca = PCA (n_komponent = 2)
zmanjšani_podatki_naključno = feature_pca.fit_transform (števke.podatki)
model_pca = PCA (n_komponent = 2)
zmanjšani_podatki_pca = model_pca.fit_transform (števke.podatki)
zmanjšani_podatki_pca.obliko
natisni (zmanjšani_podatki_naključno)
tiskanje (zmanjšana_podatkovna_pca)
Ko zaženemo zgornji delček kode, bomo videli naslednji izhod:
[[-1.2594655 21.27488324][7.95762224 -20.76873116]
[6.99192123 -9.95598191]
..
[10.8012644 -6.96019661]
[-4.87210598 12.42397516]
[-0.34441647 6.36562581]]
[[-1.25946526 21.27487934]
[7.95761543 -20.76870705]
[6.99191947 -9.9559785]
..
[10.80128422 -6.96025542]
[-4.87210144 12.42396098]
[-0.3443928 6.36555416]]
V zgornji kodi omenimo, da za nabor podatkov potrebujemo le dve funkciji.
Zdaj, ko dobro poznamo naš nabor podatkov, se lahko odločimo, kakšne algoritme strojnega učenja lahko na njem uporabimo. Poznavanje nabora podatkov je pomembno, saj se tako lahko odločimo, katere podatke lahko iz njega izločimo in s katerimi algoritmi. Pomaga nam tudi pri preizkušanju hipoteze, ki jo ugotovimo ob napovedovanju prihodnjih vrednosti.
Uporaba k-pomeni združevanje v gruče
Algoritem grozdenja k-pomeni je eno najlažjih algoritmov za nenadzorovano učenje. V tem združevanju imamo nekaj naključnih skupin in svoje podatkovne točke razvrstimo v eno od teh skupin. Algoritem k-pomeni bo poiskal najbližjo skupino za vsako od danih podatkovnih točk in jo dodelil tej gruči.
Ko je gručiranje končano, se središče gruče preračuna, podatkovnim točkam se dodelijo nove gruče, če pride do sprememb. Ta postopek se ponavlja, dokler se podatkovne točke tam ne prenehajo spreminjati, da se doseže stabilnost.
Preprosto uporabimo ta algoritem brez kakršne koli predhodne obdelave podatkov. Za to strategijo bo delček kode precej preprost:
iz sklearn import gruček = 3
k_means = grozd.KMeans (k)
# fit podatki
k_ pomeni.fit (števke.podatki)
# rezultati tiskanja
natisni (k_ pomeni.oznake _ [:: 10])
tisk (števke.cilj [:: 10])
Ko zaženemo zgornji delček kode, bomo videli naslednji izhod:
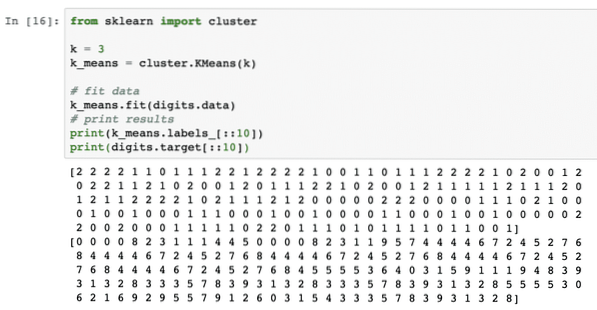
V zgornjem izhodu lahko vidimo različne grozde, ki so na voljo vsaki podatkovni točki.
Zaključek
V tej lekciji smo si ogledali izvrstno knjižnico strojnega učenja, scikit-learn. Izvedeli smo, da je v družini scikit na voljo veliko drugih modulov, in uporabili preprost algoritem k-pomeni za nabrani niz podatkov. Obstaja veliko več algoritmov, ki jih je mogoče uporabiti na naboru podatkov, razen grozdenja k-pomeni, ki smo ga uporabili v tej lekciji, zato vam priporočamo, da to storite in delite svoje rezultate.
Prosimo, delite svoje povratne informacije o lekciji na Twitterju z @sbmaggarwal in @LinuxHint.


