- 1 za resnično oz
- 0 za false
Ključni pomen logistične regresije:
- Neodvisne spremenljivke ne smejo biti večkolinearnost; če obstaja kakšen odnos, bi ga moralo biti zelo malo.
- Nabor podatkov za logistično regresijo mora biti dovolj velik, da doseže boljše rezultate.
- V naboru podatkov bi morali biti le ti atributi, ki imajo nekaj pomena.
- Neodvisne spremenljivke morajo biti v skladu z log kvote.
Za izgradnjo modela logistična regresija, uporabljamo scikit-learn knjižnica. Postopek logistične regresije v pythonu je podan spodaj:
- Uvozite vse potrebne pakete za logistično regresijo in druge knjižnice.
- Naložite nabor podatkov.
- Razumevanje neodvisnih spremenljivk nabora podatkov in odvisnih spremenljivk.
- Nabor podatkov razdelite na podatke o usposabljanju in preskusu.
- Inicializirajte model logistične regresije.
- Model prilagodite naboru podatkov o vadbi.
- Predvidite model s pomočjo testnih podatkov in izračunajte natančnost modela.
Težava: Prvi koraki so zbiranje nabora podatkov, na katerem želimo uporabiti Logistična regresija. Podatkovni nabor, ki ga bomo uporabili tukaj, je za sprejemni niz podatkov MS. Ta nabor podatkov ima štiri spremenljivke, od katerih so tri neodvisne spremenljivke (GRE, GPA, work_experience), ena pa je odvisna spremenljivka (sprejeta). Ta nabor podatkov bo pokazal, ali bo kandidat dobil sprejem na prestižni univerzi na podlagi svojih splošnih točk (GPA), GRE ali delovnih izkušenj.
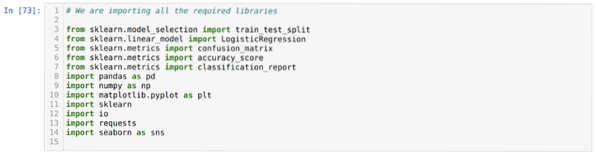
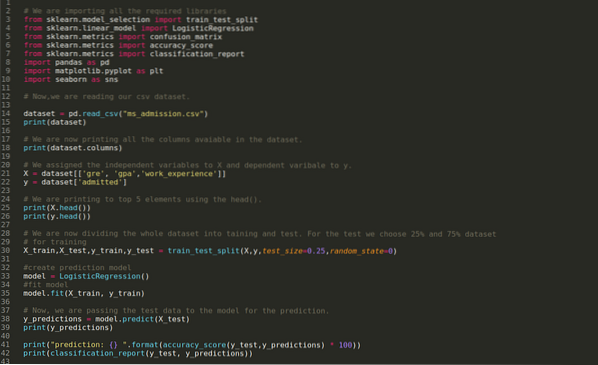
Korak 1: Uvozimo vse potrebne knjižnice, ki smo jih potrebovali za program python.
2. korak: Zdaj nalagamo svoj nabor podatkov za sprejem ms s funkcijo pandas read_csv.

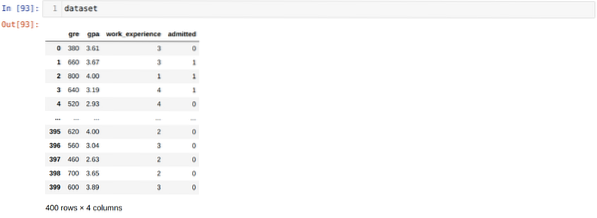
3. korak: Nabor podatkov je videti spodaj:
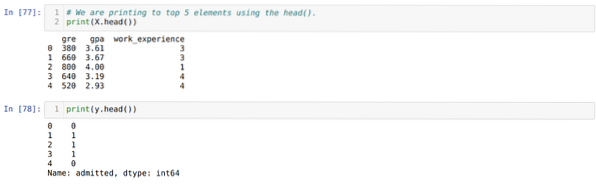
4. korak: Preverimo vse stolpce, ki so na voljo v naboru podatkov, nato pa nastavimo vse neodvisne spremenljivke na spremenljivko X in odvisne spremenljivke na y, kot je prikazano na spodnjem posnetku zaslona.

5. korak: Po nastavitvi neodvisnih spremenljivk na X in odvisnih spremenljivk na y zdaj tukaj tiskamo, da navzkrižno preverimo X in y s funkcijo head pandas.
6. korak: Zdaj bomo celoten nabor podatkov razdelili na usposabljanje in preizkušanje. Za to uporabljamo metodo train_test_split sklearna. Za test smo namenili 25% celotnega nabora podatkov, preostalih 75% nabora podatkov pa za usposabljanje.
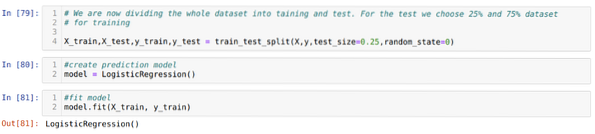
7. korak: Zdaj bomo celoten nabor podatkov razdelili na usposabljanje in preizkušanje. Za to uporabljamo metodo train_test_split sklearna. Za test smo dali 25% celotnega nabora podatkov, preostalih 75% nabora podatkov pa za usposabljanje.
Nato izdelamo model logistične regresije in prilagodimo podatke o usposabljanju.
8. korak: Zdaj je naš model pripravljen za napovedovanje, zato zdaj prenašamo testne podatke (X_test) v model in dobimo rezultate. Rezultati kažejo (y_predictions), da sta vrednosti 1 (sprejeta) in 0 (ni dovoljena).

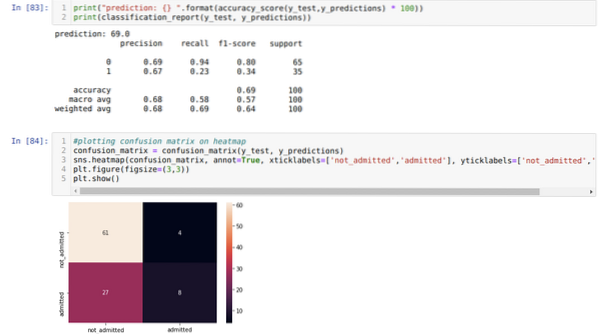
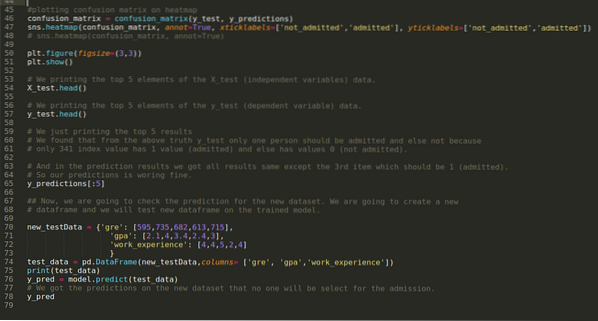
9. korak: Zdaj natisnemo poročilo o klasifikaciji in matriko zmede.
Poročilo o klasifikaciji kaže, da lahko model napove rezultate z natančnostjo 69%.
Matrica zmede prikazuje skupne podrobnosti podatkov X_test kot:
TP = resnične pozitivne vrednosti = 8
TN = resnični negativi = 61
FP = napačno pozitivni = 4
FN = Lažni negativi = 27
Torej, skupna natančnost glede na matriko zmede je:
Natančnost = (TP + TN) / Skupaj = (8 + 61) / 100 = 0.69
10. korak: Zdaj bomo rezultat preverili s tiskom. Torej, samo natisnemo 5 najboljših elementov X_test in y_test (dejanska resnična vrednost) s funkcijo head pandas. Nato natisnemo tudi 5 najboljših rezultatov napovedi, kot je prikazano spodaj:
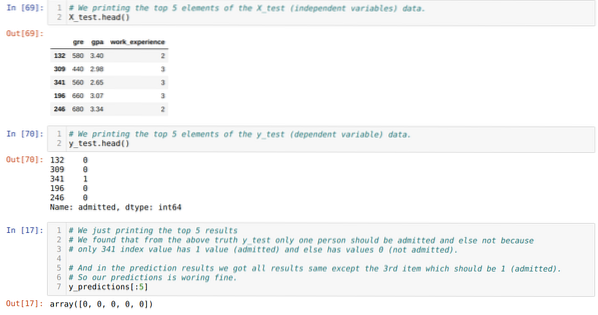
Vse tri rezultate združimo v list, da razumemo napovedi, kot je prikazano spodaj. Vidimo lahko, da je napoved poleg podatkov o 341 X_test, ki je bila resnična (1), napačna (0), sicer. Torej, naše napovedi modelov delujejo 69%, kot smo že pokazali zgoraj.

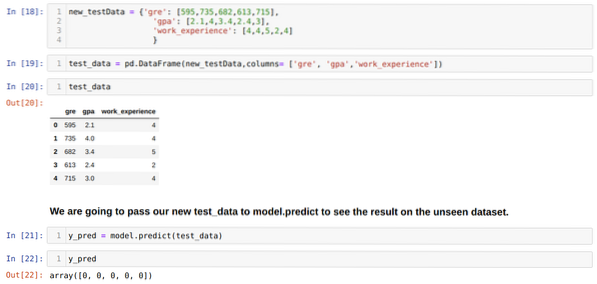
11. korak: Torej razumemo, kako se predvidevanja modelov izvajajo na nevidnem naboru podatkov, kot je X_test. Tako smo z uporabo podatkovnega okvira pand ustvarili le naključno nov nabor podatkov, ga poslali izurjenemu modelu in dobili spodnji rezultat.
Popolna koda v pythonu, podana spodaj:
Koda tega spletnega dnevnika je skupaj z naborom podatkov na voljo na naslednji povezavi
https: // github.com / shekharpandey89 / logistic-regression


