Podatkovna baza Elasticsearch
Elasticsearch je ena izmed najbolj priljubljenih baz podatkov NoSQL, ki se uporablja za shranjevanje in iskanje besedilnih podatkov. Temelji na tehnologiji indeksiranja Lucene in omogoča iskanje v milisekundah na podlagi indeksiranih podatkov.
Tukaj je definicija, ki temelji na spletni strani Elasticsearch:
Elasticsearch je odprtokodni distribucijski RESTful iskalni in analitični motor, ki lahko reši vedno večje število primerov uporabe.
To je bilo nekaj besed na visoki ravni o Elasticsearchu. Tukaj podrobno razumemo koncepte.
- Porazdeljeno: Elasticsearch razdeli podatke, ki jih vsebuje, na več vozlišč in jih uporablja mojster-suženj algoritem interno
- POČITEK: Elasticsearch podpira poizvedbe v zbirki podatkov prek REST API-jev. To pomeni, da lahko uporabljamo preproste klice HTTP in metode HTTP, kot so GET, POST, PUT, DELETE itd. za dostop do podatkov.
- Iskalni in analitični motor: ES podpira zelo analitične poizvedbe, ki se izvajajo v sistemu in so lahko sestavljene iz agregiranih poizvedb in več vrst, kot so strukturirane, nestrukturirane in geo poizvedbe.
- Horizontalno prilagodljivo: Tovrstno spreminjanje obsega se nanaša na dodajanje več strojev obstoječi gruči. To pomeni, da je ES sposoben sprejeti več vozlišč v svoji gruči in ne zagotoviti časa izpada za potrebne nadgradnje sistema. Oglejte si spodnjo sliko, da boste razumeli koncepte skaliranja:
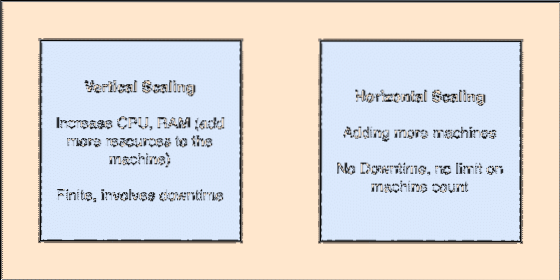
Navpično in vodoravno skaliranje
Uvod v bazo podatkov Elasticsearch
Če želite začeti uporabljati Elasticsearch, ga morate namestiti na stroj. Če želite to narediti, preberite Namesti ElasticSearch v Ubuntuju.
Prepričajte se, da imate aktivno namestitev ElasticSearch, če želite preizkusiti primere, ki jih predstavljamo kasneje v lekciji.
Elasticsearch: Pojmi in komponente
V tem poglavju bomo videli, katere komponente in koncepti so v središču Elasticsearch. Razumevanje teh konceptov je pomembno, da razumemo, kako deluje ES:
- Grozd: Grozd je zbirka strežniških strojev (vozlišč), ki hrani podatke. Podatki so razdeljeni med več vozlišč, tako da jih je mogoče podvajati, pri strežniku ES pa se ne zgodi ena točka okvare (SPoF). Privzeto ime gruče je elastično iskanje. Vsako vozlišče v gruči se na gručo poveže z URL-jem in imenom gruče, zato je pomembno, da to ime ostane jasno in jasno.
- Vozlišče: Stroj vozlišč je del strežnika in se imenuje kot en stroj. Shranjuje podatke in omogoča geslu indeksiranje in iskanje, skupaj z drugimi vozlišči.
Zaradi koncepta vodoravnega skaliranja lahko v gručo ES tako rekoč dodamo neskončno število vozlišč, da dobimo veliko več moči in indeksiranja.
- Kazalo: Kazalo je zbirka dokumentov z nekoliko podobnimi značilnostmi. Indeks je precej podoben zbirki podatkov v okolju, ki temelji na SQL.
- Tip: Tip se uporablja za ločevanje podatkov med istim indeksom. Na primer, baza podatkov / indeks strank ima lahko več vrst, kot so uporabnik, vrsta_plačila itd.
Upoštevajte, da so tipi zastareli iz ES v6.0.0 naprej. Tukaj preberite, zakaj je bilo to storjeno.
- Dokument: Dokument je najnižja raven enote, ki predstavlja podatke. Predstavljajte si ga kot objekt JSON, ki vsebuje vaše podatke. V indeksu je mogoče indeksirati toliko dokumentov.
Vrste iskanja v Elasticsearch
Elasticsearch je znan po svojih zmožnostih iskanja v skoraj realnem času in prilagodljivosti, ki jo ponuja glede na vrsto podatkov, ki se indeksirajo in iščejo. Začnimo s preučevanjem uporabe iskanja z različnimi vrstami podatkov.
- Strukturirano iskanje: Ta vrsta iskanja se izvaja na podatkih, ki imajo vnaprej določeno obliko, kot so datumi, časi in številke. S predhodno določenim formatom prihaja prilagodljivost izvajanja običajnih operacij, kot je primerjava vrednosti v razponu datumov. Zanimivo, tudi besedilni podatki so lahko strukturirani. To se lahko zgodi, če ima polje določeno število vrednosti. Ime baze podatkov je lahko na primer MySQL, MongoDB, Elasticsearch, Neo4J itd. Pri strukturiranem iskanju je odgovor na poizvedbe da ali ne.
- Iskanje po celotnem besedilu: Ta vrsta iskanja je odvisna od dveh pomembnih dejavnikov, Ustreznost in Analiza. Z ustreznostjo določimo, kako dobro se nekateri podatki ujemajo s poizvedbo, tako da določimo rezultat rezultatov. To oceno zagotavlja ES sama. Analiza se nanaša na razbijanje besedila na normalizirane žetone za ustvarjanje obrnjenega indeksa.
- Večpoljno iskanje: Ker se število analitičnih poizvedb vedno povečuje glede shranjenih podatkov v ES, se običajno ne soočamo samo s poizvedbami s preprostim ujemanjem. Narasle so zahteve za izvajanje poizvedb, ki se raztezajo v več poljih in imajo razvrščen razvrščen seznam podatkov, ki nam ga vrne sama baza podatkov. Na ta način so lahko podatki na voljo končnemu uporabniku na veliko bolj učinkovit način.
- Proimity Matching: Poizvedbe danes so veliko več kot le ugotavljanje, ali nekateri besedilni podatki vsebujejo drug niz ali ne. Gre za vzpostavitev razmerja med podatki, tako da jih je mogoče točkovati in ujemati s kontekstom, v katerem se podatki ujemajo. Na primer:
- Žoga je zadela Johna
- John je zadel žogo
- John je kupil novo žogo, ki jo je zadel Jaen vrt
Poizvedba za ujemanje bo med iskanjem našla vse tri dokumente Zadetek z žogo. Bližnje iskanje nam lahko pove, kako daleč se ti dve besedi pojavita v isti vrstici ali odstavku, zaradi česar se ujemata.
- Delno ujemanje: Pogosto moramo zagnati poizvedbe z delnim ujemanjem. Delno ujemanje nam omogoča izvajanje poizvedb, ki se delno ujemajo. Da si to predstavimo, si oglejmo podobne poizvedbe, ki temeljijo na SQL:
Poizvedbe SQL: Delno ujemanje
KJE IME KOT "% john%"
IN ime KAKO "% red%"
IN poimenuj KOT "% garden%"V nekaterih primerih moramo poizvedbe z delnim ujemanjem zagnati le, če jih lahko obravnavamo kot tehnike surove sile.
Integracija s Kibana
Ko gre za analitični mehanizem, moramo običajno izvajati poizvedbe za analizo v domeni Business-Intelligence (BI). Ko gre za poslovne analitike ali analitike podatkov, ne bi bilo pravično domnevati, da ljudje poznajo programski jezik, ko želijo vizualizirati podatke, ki so prisotni v ES Cluster. To težavo reši Kibana. Kibana ponuja toliko prednosti za BI, da si lahko ljudje dejansko vizualizirajo podatke z odlično prilagodljivo nadzorno ploščo in si podatke ogledajo neaktivno. Poglejmo si nekaj njegovih prednosti tukaj.
Interaktivne karte
V jedru Kibane so interaktivne lestvice, kot so te:
Kibana je podprt z različnimi vrstami grafikonov, kot so tortni diagrami, sončni sunki, histogrami in še veliko več, ki uporablja celotne agregatne zmožnosti ES.
Podpora za preslikavo
Kibana podpira tudi celotno geo-agregacijo, ki nam omogoča zemljevid naših podatkov. Ali ni to v redu?!
Vnaprej zgrajena združevanja in filtri
S predhodno vgrajenimi agregacijami in filtri je mogoče na nadzorni plošči Kibana dobesedno razdrobiti, spustiti in zagnati zelo optimizirane poizvedbe. Z le nekaj kliki je mogoče zagnati združene poizvedbe in predstaviti rezultate v obliki interaktivnih grafikonov.
Enostavna distribucija nadzornih plošč
S Kibana je tudi nadzorne plošče zelo enostavno deliti z veliko širšim občinstvom, ne da bi na njej spreminjali nadzor s pomočjo načina samo na nadzorni plošči. Nadzorne plošče lahko enostavno vstavimo v naš interni wiki ali spletne strani.
Predstavljene slike, posnete s strani izdelka Kibana.
Uporaba Elasticsearch
Če si želite ogledati podrobnosti primerka in informacije o gruči, zaženite naslednji ukaz: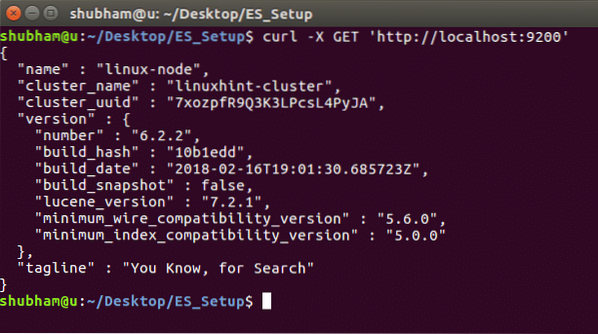
Zdaj lahko poskusimo vstaviti nekaj podatkov v ES z naslednjim ukazom:
Vstavljanje podatkov
curl \-X POST 'http: // localhost: 9200 / linuxhint / hello / 1' \
-H 'Content-Type: application / json' \
-d '"name": "LinuxHint"' \
Tukaj dobimo s tem ukazom:
Poskusimo zdaj pridobiti podatke:
Pridobivanje podatkov
curl -X GET 'http: // localhost: 9200 / linuxhint / hello / 1'Ko zaženemo ta ukaz, dobimo naslednji izhod:
Zaključek
V tej lekciji smo preučili, kako lahko začnemo uporabljati ElasticSearch, ki je odličen Analytics Engine in ponuja odlično podporo za skoraj sprotno iskanje prostega besedila.


